Основные характеристики моделей данных
Файл (таблица) - совокупность экземпляров записей одной структуры.
В структуре записи файла указываются поля, значения которых являются ключами первичными (ПК), которые идентифицируют экземпляр записи, и вторичными (ВК), которые выполняют роль поисковых или группировочных признаков (по значению вторичного ключа можно найти несколько записей).
2.2. Системы управления базами данных
По мере увеличения объемов и структурной сложности хранимой информации, а также расширения круга потребителей информации, определилась необходимость создания удобных и эффективных систем интеграции хранимых данных и управления ими. Теперь создание базы данных, ее поддержка и обеспечение доступа пользователей к ней осуществляются централизованно с помощью специального программного инструментария - системы управления базами данных (СУБД).
Система управления базами данных (СУБД) - это комплекс программных и языковых средств, необходимых для создания баз данных, поддержания их в актуальном состоянии и организации поиска в них необходимой информации.
Первые СУБД, поддерживающие opганизацию и ведение БД, появились в конце 60-х годов.
Использование СУБД обеспечивает лучшее управление данными, более совершенную организацию файлов и более простое обращение к ним по сравнению с обычными способами хранения информации.
3. МОДЕЛИ ДАННЫХ
И ИХ ВИДЫ
Ядром любой базы данных является модель данных. Модель данных представляет собой множество структур данных, ограничений целостности и операций манипулирования данными. С помощью модели данных могут быть представлены объекты предметной области и взаимосвязи между ними.
Модель данных - совокупность структур данных и операций их обработки.
По способу установления связей между данными СУБД основывается на использовании трёх основных видов модели: иерархической, сетевой или реляционной; на комбинации этих моделей или на некотором их подмножестве.
Однако различия между этими моделями постепенно стираются, что обусловлено прежде всего интенсивными работами в области баз знаний (БЗ) и объектно-ориентированной инфотехнологией, о которой будет идти речь ниже.
Каждая из указанных моделей обладает характеристиками, делающими ее наиболее удобной для конкретных приложений. Одно из основных различий этих моделей состоит в том, что для иерархических и сетевых СУБД их структура часто не может быть изменена после ввода данных, тогда как для реляционных СУБД структура может изменяться в любое время. С другой стороны, для больших БД, структура которых остается длительное время неизменной, и постоянно работающих с ними приложений с интенсивными потоками запросов на БД-обслуживание именно иерархические и сетевые СУБД могут оказаться наиболее эффективными решениями, ибо они могут обеспечивать более быстрый доступ к информации БД, чем реляционные СУБД.
4. ИЕРАРХИЧЕСКАЯ
МОДЕЛЬ ДАННЫХ
Иерархическая структура представляет совокупность элементов, связанных между собой по определенным правилам. Объекты, связанные иерархическими отношениями, образуют ориентированный граф (перевернутое дерево).
К основным понятиям иерархической структуры относятся: уровень, элемент (узел), связь.
Узел - это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне. Иерархическое дерево имеет только одну вершину (корень дерева), не подчиненную никакой другой вершине и находящуюся на самом верхнем (первом) уровне. Зависимые (подчиненные) узлы находятся на втором, третьем и т.д. уровнях. Количество деревьев в базе данных определяется числом корневых записей.
К каждой записи базы данных существует только один (иерархический) путь от корневой записи.
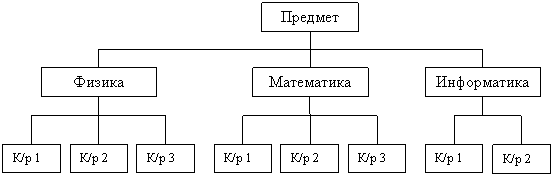 |
Каждому узлу структуры соответствует одинсегмент, представляющий собой поименованный линейный кортежполейданных. Каждому сегменту (кроме S1-корневого) соответствует один входной и несколько выходных сегментов. Каждыйсегмент структуры лежит на единственном иерархическом пути, начинающемся откорневого сегмента.
Следует отметить, что в настоящее время не разрабатываются СУБД, поддерживающие на концептуальном уровне только иерархические модели. Как правило, использующие иерархический подход системы, допускают связываниедревовидных структур между собой и/или установление связей внутри них. Это приводит к сетевым даталогическим моделям СУБД.
К основным недостаткамиерархических моделей следует отнести: неэффективность реализации отношений типа N:N, медленный доступ к сегментам данных нижних уровней иерархии, четкая ориентация на определенные типы запросов и др. В связи сэтими недостатками ранее созданные иерархические СУБД подвергаются существенным модификациям, позволяющим поддерживать более сложные типы структур и, в первую очередь, сетевые и их модификации.
5. СЕТЕВАЯ
МОДЕЛЬ ДАННЫХ
В сетевой структуре при тех же основных понятиях (уровень, узел, связь) каждый элемент может быть связан с любым другим элементом.
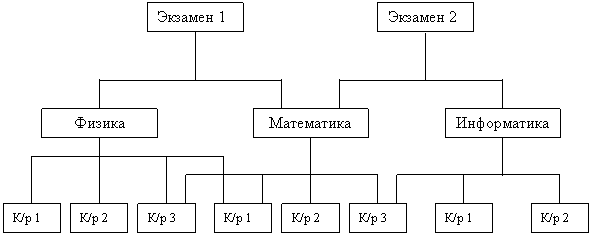
Сетевая модель СУБД во многом подобна иерархической: если в иерархической модели для каждого сегмента записи допускается только один входной сегмент при N выходных, то в сетевой модели для сегментов допускается несколько входных сегментов наряду с возможностью наличия сегментов без входов с точки зрения иерархической структуры.
Графическое изображение структуры связей сегментов такого типа моделей представляет собой сеть. Сегменты данных в сетевых БД могут иметь множественные связи с сегментами старшего уровня. При этом направление и характер связи в сетевых БД не являются столь очевидными, как в случае иерархических БД. Поэтому имена и направление связей должны идентифицироваться при описании БД.
Таким образом, под сетевой СУБД понимается система, поддерживающая сетевую организацию: любая запись, называемая записью старшего уровня, может содержать данные, которые относятся к набору других записей, называемых записями подчиненного уровня. Возможно обращение ко всем записям в наборе, начиная с записи старшего уровня. Обращение к набору записей реализуется по указателям.
В рамках сетевых СУБД легко реализуются и иерархические даталогические модели.
Сетевые СУБД поддерживают сложные соотношения между типами данных, что делает их пригодными во многих различных приложениях. Однако пользователи таких СУБД ограничены связями, определенными для них разработчиками БД-приложений.
Более того, подобно иерархическим сетевые СУБД предполагают разработку БД приложений опытными программистами и системными аналитиками.