Разработка технологического процесса по организации обработки информации для составления аналитических обзоров бизнес-процессов на базе системы SAP BWРефераты >> Программирование и компьютеры >> Разработка технологического процесса по организации обработки информации для составления аналитических обзоров бизнес-процессов на базе системы SAP BW
ETL является жизненно важной и, возможно, наиболее проблематичной частью хранения данных, а значит таковой она является и для всего проекта управления бизнес-информацией. Надо определять правильные источники данных, оценивать значимость и достоверность этих данных и отслеживать потоки данных. Необходимо удостовериться, что процесс ETL охватывает и загружает весь диапазон требуемых данных, одновременно избегая перегрузки за счет "лишних" данных. Данные необходимо собрать и очистить, чтобы удалить дубликаты и неправильные значения. И их необходимо обогатить (агрегировать), чтобы преобразовать в удобную для практического применения информацию.
Экстракцию данных можно выполнять на двух уровнях: на уровне приложения и на уровне базы данных или файла ("техническом уровне"). На уровне приложения экстракция данных выполняется в виде бизнес-объектов.
Так как он быстрее и проще, то этот метод наиболее предпочтительный, особенно когда в экстракции участвует много приложений и требуется длительный период времени для реализации данной задачи. Например, такой бизнес-объект, как "заказ клиента", может быть представлен несколькими основными таблицами СУБД. Отношение между таблицами определяется логикой приложения. Экстракция на уровне базы данных или файла означает, что полный набор данных и соответствующие метаданные берутся непосредственно их этих разных таблиц, а это трудная задача, занимающая много времени и требующая высокой квалификации[7].
Однако есть ситуации, при которых требуется экстракция на уровне базы данных или файла:
- данные хранятся в файлах (плоских файлах);
- данные отправляются через XML;
- данные существуют в базах данных, которые находятся. под прежними или специальными приложениями;
- структуры таблицы прозрачны;
- экстракция на уровне приложения невозможна.
2.4.2 Экстракция, преобразование и загрузка (ETL) в SAP BW
SAP BW предоставляет пользователям широкий набор возможностей ETL, который поддерживает экстракцию данных на уровнях приложения и файла. Он также предлагает открытые интерфейсы для внешних инструментов ETL, которые обеспечивают дополнительные возможности. Данные могут загружаться практически из любого источника (рисунок 5).
На рисунке 5 данные становятся доступными в SAP BW в соответствии с определениями исходных данных в каждом источнике данных. Фактические данные из разных источников физически хранятся в объекте Persistent Staging Area (PSA), прозрачной таблице базы данных. PSA - это первичная область хранения в информационной модели SAP BW, в которой содержаться данные, запрошенные в неизменном виде из исходной системы. PSA создается для каждого источника данных и исходной системы[3].
Данные перемещаются из источника данных в инфо-источник (рисунок 4). В инфо-источнике содержатся данные, которые связаны друг с другом с точки зрения бизнеса.
Когда данные перемещаются из источника данных в инфо-источник, они очищаются и преобразовываются при помощи правил переноса. SAP BW предлагает богатую библиотеку правил переноса, которые прилагают бизнес-логику к данным через такие действия, как преобразование даты и времени, строковые операции и агрегация. Эти правила можно легко применять при помощи формул, что означает, что необходимость в кодировании отсутствует.
Для поддержки мэппинга (мэппинг - процесс установления взаимно однозначного соответствия между объектами) в SAP BW отдельные поля источника данных присваиваются соответствующим инфо-объектам, которые составляют инфо-источник. Также в процессе мэппинга точно определяется, какие данные будут переноситься в инфо-источник из источника данных.
В SAP BW данные переносятся в инфо-пакетах. Инфо-пакет определяет, какие данные, содержащиеся в источнике данных, должны запрашиваться из исходной системы. Инфо-пакет может запрашивать как переменные, так и основные данные при помощи точных параметров, например, только контроллинговая единица 0001 за октябрь 2001 года. Это означает, что инфо-пакеты могут описывать целевые поднаборы данных, содержащиеся в источнике данных. С помощью инструментальных средств администратора SAP BW можно планировать и отслеживать перенос инфо-пакетов.
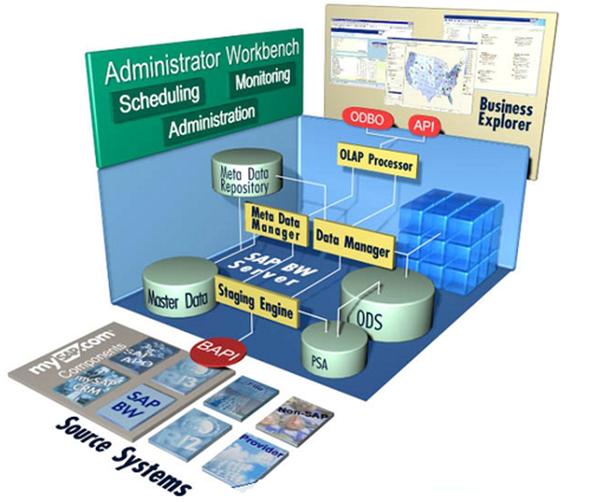
Рисунок 5 - Экстракция, преобразование и загрузка (ETL) в SAP BW
2.5 Хранилище операционных данных (ODS)
Хранилище данных (рисунок 6) является относительно статичным. Оно спроектировано для оптимизации запросов на крупные объемы исторических и агрегированных данных, для поддержания в основном стратегического, а не оперативного процесса принятия решений.
Хранилище операционных данных, с другой стороны, спроектировано для поддержки большого количества запросов на небольшие объемы данных, которые часто обновляются. Оно хранит подробные данные и поддерживает процесс ежедневного принятия решений на тактическом уровне. Точные определения хранилища операционных данных бывают разными, но SAP рассматривает его как информационную среду "почти" реального времени, которая поддерживает оперативную отчетность, взаимодействуя с существующими операционными системами, хранилищами данных или аналитическими приложениями.
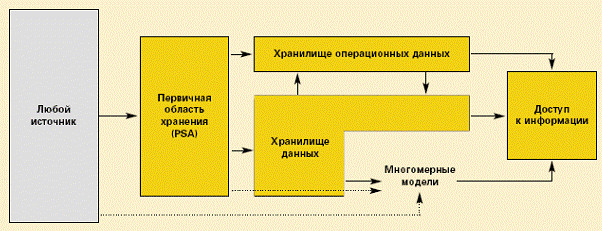
Рисунок 6 – Хранилище данных SAP BW
Хранилище операционных данных играет важную роль, потому что основные области бизнеса во многом зависят от точных и своевременных данных. Оперативной информацией должны регулярно пользоваться поставщики и партнеры, а прямой доступ к нужным данным играет критическую роль в обслуживании клиентов. Хранилище операционных данных помогает использовать данные предприятия для тактических операций, делает их доступными для основных сотрудников и помогает в привлечении большого количества пользователей в этих областях.
SAP BW предоставляет гибкий доступ к данным в хранилище данных (рисунок 6), хранилище операционных данных и многомерных моделях. Данные можно загружать из Persistent Staging Area непосредственно в хранилище операционных данных и хранилище данных. Их также можно загружать непосредственно в многомерные инфо-кубы, если нет необходимости в очистке, преобразовании или консолидации данных, т.е. когда исходная система обеспечивает необходимый уровень качества данных.
В SAP BW ODS-объекты и связанные с ними правила обновления, которые обрабатывают поток данных между объектами, создают хранилище операционных данных. Хранилище операционных данных может состоять из нескольких уровней ODS-объектов, разрешая дальнейшую консолидацию данных. Например, ODS-объект, который содержит данные об "объеме отгрузки" можно объединить с ODS-объектом, который описывает "входящие заказы" для создания консолидированного объекта "заказов и фактических данных" для продукта. Равно тому, как можно создавать уровни ODS-объектов, можно взвешивать преимущество анализа консолидированных данных относительно растущих затрат на хранение, необходимых для создания дополнительных объектов[5].