Иерархические структуры в реляционных базах данныхРефераты >> Программирование и компьютеры >> Иерархические структуры в реляционных базах данных
Сетевая модель более симметрична, чем иерархическая модель. Однако процедуры (обновления) значительно сложнее проблема состоит в следующем: всегда имеются две стратегии для определения места одного экземпляра записи, первая начинается с "владельца" и просмотра его цепочки для выбора звена, а другая начинается с "подчиненного звена" и просмотра его цепочки для выбора "владельца". Как пользователь может решить, какую стратегию принять? Выбор и здесь имеет большое значение. Как в иерархических, так и сетевых СУБД при описании данных обычно указываются характеристики записей каждого типа, способствующие более эффективному размещению данных во внешней памяти и более быстрому доступу к ним. К таким характеристикам относятся: размеры полей записи (минимальные, средние, максимальные), состав ключа, допустимый набор символов, интервалы значений и т.д.
Иерархические и сетевые базы данных часто называют базами данных с навигацией. Это название отражает технологию доступа к данным, используемую при написании обрабатывающих программ на языке манипулирования данными. При этом, очевидно, что доступ к данным по путям, не предусмотренным при создании базы данных, может потребовать неразумно большого времени. Повышая эффективность доступа к данным и сокращая таким образом время ответа на запрос, принцип навигации вместе с этим повышает и степень зависимости программ и данных. Обрабатывающие программы оказываются жестко привязанными к текущему состоянию структуры базы данных и должны быть переписаны при ее изменениях. Операции модификации и удаления данных требует переустановки указателей, а манипулирование данными остается записеориентированным. Кроме того, принцип навигации не позволяет существенно повышать уровень языка манипулирования данными, чтобы сделать его доступным пользователю-непрограммисту, или даже программисту-непрофессионалу. Для поиска записи-цели в иерархической или сетевой структуре программист должен вначале опеределить путь доступа, а затем просмотреть все записи, лежащие на этом пути, - шаг за шагом.
Насколько запутанной являются схемы представления иерархических и сетевых баз данных, настолько и трудоемким является проектирование конкретных прикладных систем на их основе. Как показывает, опыт длительные сроки разработки прикладных систем нередко приводят к тому, что они постоянно находятся в стадии разработки и доработки.
Указанные и некоторые другие проблемы, с которыми столкнулись разработчики и пользователи иерархических и сетевых систем послужили стимулом к созданию реляционной модели данных и реляционных СУБД.
2.1. Файловая модель
Кратко рассмотрим файловую модель, неправомерно относимую довольно часто к СУБД. Файловая модель представляет собой набор файлов данных определенной структуры, но связь между данными этих файлов отсутствует. Естественно, программные средства работы с таким образом организованной инфобазой могут устанавливать связь между данными ее файлов, но на концептуальном уровне файлы модели являются независимыми. Системы, обеспечивающие работу с файловыми инфобазами, называют системами управления файлами (СУФ) и они оказываются весьма эффективными во многих приложениях. СУФ используются на всех классах ЭВМ, но особенно они распространены для обработки информации на ПК. При этом во многих источниках они фигурируют в качестве СУБД. Файловые системы легко осваиваются, достаточно просты и эффективны в использовании и, как правило, для работы с ними используются простые языки запросов либо и вовсе ограничиваются набором программ-утилит. Такие системы обычно поддерживают работу с небольшим числом файлов, содержащих ограниченное число записей с небольшим количеством полей.
Иерархические модели СУБД имеют древовидную структуру, когда каждому узлу структуры соответствует один сегмент, представляющий собой поименованный линейный кортеж полей данных. Каждому сегменту (кроме S1-корневого) соответствует один входной и несколько выходных сегментов (рис. 3а). Каждый сегмент структуры лежит на единственном иерархическом пути, начинающемся от корневого сегмента.
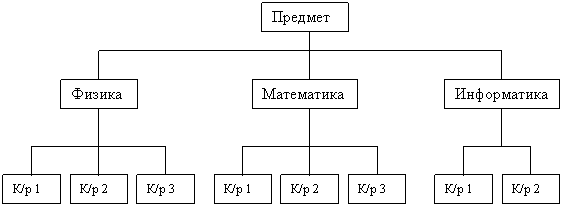 |
Рис. а)
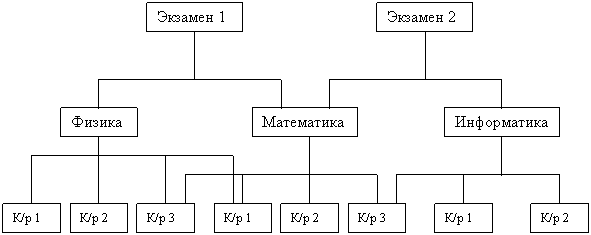 |
Рис. б)
Рис. 3. Структура иерархической (а) и сетевой (б) СУБД
Для описания такой логической организации данных ЯОД достаточно предусматривать для каждого сегмента данных только идентификацию входного для него сегмента. Так как в иерархической модели каждому входному сегменту данных соответствует N выходных, то такие модели весьма удобны для представления отношений типа 1:N впредметной области. Следует отметить, что в настоящее время не разрабатываются СУБД, поддерживающие на концептуальном уровне только иерархические модели. Как правило, использующие иерархический подход системы допускают связывание древовидных структур между собой и/или установление связей внутри них. Это приводит к сетевым даталогическим моделям СУБД. К основным недостаткам иерархических моделей следует отнести: неэффективность реализации отношений типа N:N, медленный доступ к сегментам данных нижних уровней иерархии, четкая ориентация на определенные типы запросов и др. В связи с этими недостатками ранее созданные иерархические СУБД подвергаются существенным модификациям, позволяющим поддерживать более сложные типы структур и, в первую очередь, сетевые и их модификации. Сетевая даталогическая модель СУБД во многом подобна иерархической: если в иерархической модели (рис. 3а) для каждого сегмента записи допускается только один входной сегмент при N выходных, то в сетевой модели для сегментов допускается несколько входных сегментов наряду с возможностью наличия сегментов без входов с точки зрения иерархической структуры. На рис. 3б представлен простой пример сетевой структуры, полученной на основе модификации иерархической структуры (рис. 3а). Графическое изображение структуры связей сегментов такого типа моделей представляет собой сеть. Сегменты данных в сетевых БД могут иметь множественные связи с сегментами старшего уровня. При этом направление и характер связи в сетевых БД не являются столь очевидными, как в случае иерархических БД. Поэтому имена и направление связей должны идентифицироваться при описании БД средствами ЯОД.
Таким образом, под сетевой СУБД понимается система, поддерживающая сетевую организацию: любая запись, называемая записью старшего уровня, может содержать данные, которые относятся к набору других записей, называемых записями подчиненного уровня. Возможно обращение ко всем записям в наборе, начиная с записи старшего уровня. Обращение к набору записей реализуется по указателям. В рамках сетевых СУБД легко реализуются и иерархические даталогические модели. Сетевые СУБД поддерживают сложные соотношения между типами данных, что делает их пригодными во многих различных приложениях. Однако пользователи таких СУБД ограничены связями, определенными для них разработчиками БД-приложений. Более того, подобно иерархическим сетевые СУБД предполагают разработку БД приложений опытными программистами и системными аналитиками.