Автоматизация, обработка документов, распознавание документовРефераты >> Программирование и компьютеры >> Автоматизация, обработка документов, распознавание документов
Итак, показатель времени распознавания у программ совершенно разный, и сказать, какой из них быстрее, довольно сложно. Однако нельзя не заметить, что у Fine Reader 5.0 время распознавания напрямую зависит от качества оригинала: она старается распознать максимально много и поэтому затрачивает больше времени на распознавание изображения плохого качества. Ну а у Cuneiform 2000 время распознавания не настолько зависит от качества оригинала, поэтому распознавание занимает меньше времени, но из-за этого страдает качество. Вывод: Fine Reader 5.0 лучше всего использовать при распознавании как хорошего, так и плохого исходного материала. Ну, а Cuneiform 2000 в лучшем свете выглядит при распознавании среднего и чуть выше среднего качества оригиналов, т. к. при этом он тратит время на распознавание гораздо меньше, а качество лишь немного уступает победителю данного теста - Fine Reader.
Таблицы и формы
На этом этапе мы рассмотрим, насколько точно будет производиться определение таблиц и форм. Для того чтобы провести его более точно, мы возьмем два основных вида таблиц и один документ договора.
|
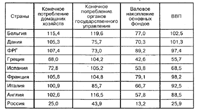
Для первого примера мы используем небольшую таблицу (рис. 15).
|
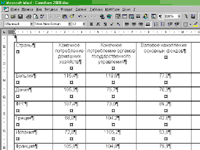
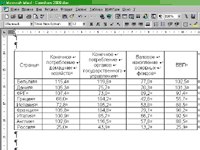
Таким образом, мы получили две идентичные таблицы (за исключением форматирования), недостатки которых в наших программах следующие: в Fine Reader 5.0 каждая ячейка заканчивается ненужным вводом (рис. 16), а Cuneiform 2000 (рис. 17) сохраняет разбивку на строки за счет вставки символа "конец строки" (Shift+Enter в MS Word).
Теперь можно взять более сложную таблицу (рис. 18).
|

При попытке разметить ее автоматически только Fine Reader нашла здесь какое-то подобие таблицы, ну а Cuneiform 2000 вообще решил, что здесь находится только текст. И только после того как вручную выделили табличный блок, программы решили распознавать таблицу.
Результаты распознавания мы видим на рис. 19, 20. Наиболее точно и близко к оригиналу у нас оказался Fine Reader 5.0, но все же не совсем так, как бы хотелось. Cuneiform 2000 вообще решил, что в таблице вся сетка должна быть полностью видимой - после таких распознаваний придется еще повозиться с таблицей достаточно основательно. Тем более Cuneiform 2000 еще не совсем точно распознал текст в самой таблице.
|
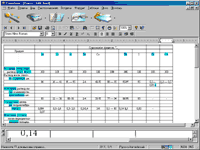
Для того чтобы хорошо и наиболее точно распознавалась таблица, можно самому отредактировать вертикальные и горизонтальные линии таблицы до распознавания текста. Это доступно в обеих программах.
Проведя исследование на распознавание таблиц, мы переходим к формам. Что же мы в данном случае под ними понимаем? А все очень просто: анкеты, договора и прочие документы, содержащие достаточно сложное оформление. Если у вас возникает вопрос, а зачем такое исследование проводить, то очень просто привести пример из жизни. Вам нужно изменить текст договора или анкеты имеющегося у вас образца, а в электронном виде его у вас нет. Время на набор и оформление ограничено, поэтому приходится использовать программу распознавания.
Итак, покончим с лирикой и возьмемся за дело. Образцом для нашего теста послужит стандартный договор найма.
При автоматической разметке страницы на блоки возникает примерно такая же ситуация, как при определении сложной таблицы, поэтому мы всю страницу определяем единым текстовым блоком вручную. Это приходится делать, поскольку в Fine Reader страница разделяется на три блока, а в Cuneiform 2000 - порядка пятнадцати.
В Fine Reader спустя 50 с мы получаем уже готовый договор, ну а в Cuneiform 2000 ждем всего 10 с, но документ в результате требует исправлений. Например, некоторые точки распознались запятыми, а вместо символа номер (№) получаем пару других символов, и точность распознавания самого текста немного страдает. Однако само форматирование договора в обеих программах сохранилось достаточно точно.
Результаты: при распознавании простой таблицы Cuneiform 2000 оказался лучше, чем Fine Reader 5.0.
При работе со сложной таблицей пришлось вручную определять блок таблицы, т. к. при автоматическом определении блоков обе программы ее не опознали вообще как таблицу. Когда это, наконец, произошло, обе полученные таблицы требовали довольно серьезной редакции, но все-таки Fine Reader показал лучший результат.
|

При распознавании договора (или формы) он же вышел на первое место, правда, при этом затратил в пять раз больше времени, чем Cuneiform 2000, зато распознал более точно, и нам меньше надо было бы править (достойное применение для работы этих программ).