Современные методы позиционирования и сжатия звукаРефераты >> Программирование и компьютеры >> Современные методы позиционирования и сжатия звука
С точки зрения частоты давление звуковой волны можно выразить так:
Pff(f) = Zo V(f) exp(- i 2 pi r/c) / r где "f" это частота в герцах (Hz), i = sqrt(-1), а V(f) получается в результате применения преобразования Фурье к скорости распространения звуковой волны V(t). Таким образом, задержки при распространении звуковой волны можно охарактеризовать "phase factor", т.е. фазовым коэффициентом exp(- i 2 pi r /c). Или, говоря словами, это означает, что функция преобразования в "free field" Pff(f) просто является результатом произведения масштабирующего коэффициента Zo, фазового коэффициента exp(- i 2 pi r /c) и обратно пропорциональна расстоянию 1/r. Заметим, что возможно более рационально использовать традиционную циклическую частоту, равную 2*pi*f чем просто частоту.
Если поместить в среду распространения звуковых волн человека, тогда звуковое поле вокруг человека искажается за счет дифракции (рассеивания или иначе говоря различие скоростей распространения волн разной длины), отражения и дисперсии (рассредоточения) при контакте человека со звуковыми волнами. Теперь все тот же источник звука будет создавать несколько другое давление звука P(t) на барабанную перепонку в ухе человека. С точки зрения частоты это давление обозначим как P(f). Теперь, P(f), как и Pff(f) также содержит фазовый коэффициент, чтобы учесть задержки при распространении звуковой волны и вновь давление ослабевает обратно пропорционально расстоянию. Для исключения этих концептуально незначимых эффектов HRTF функция H определяется как соотношение P(f) и Pff(f). Итак, строго говоря, H это функция, определяющая коэффициент умножения для значение давления звука, которое будет присутствовать в центре головы слушателя, если нет никаких объектов на пути распространения волны, в давление на барабанную перепонку в ухе слушателя.
Обратным преобразованием Фурье функции H(f) является функция H(t), представляющая собой HRIR (Head-Related Impulse Response). Таким образом, строго говоря, HRIR это коэффициент (он же есть отношение давлений, т.е. безразмерен; это просто удобный способ загнать в одну букву в формуле очень сложный параметр), который определяет воздействие на барабанную перепонку, когда звуковой импульс испускается источником звука, за исключением того, что мы сдвинули временную ось так, что t=0 соответствует времени, когда звуковая волна в "free field" достигнет центра головы слушателя. Также мы масштабировали результаты таким образом, что они не зависят от того, как далеко источник звука расположен от человека, относительно которого производятся все измерения.
Если пренебречь этим временным сдвигом и масштабированием расстояния до источника звука, то можно просто сказать, что HRIR - это давление воздействующее на барабанную перепонку, когда источник звука является импульсным.
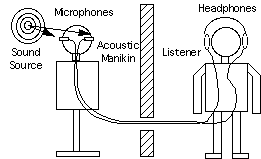
Напомним, что интегральным преобразованием Фурье функции HRIR является HRTF функция. Если известно значение HRTF для каждого уха, мы можем точно синтезировать бинауральные сигналы от монофонического источника звука (monaural sound source). Соответственно, для разного положения головы относительно источника звука задействуются разные HRTF фильтры. Библиотека HRTF фильтров создается в результате лабораторных измерений, производимых с использованием манекена, носящего название KEMAR (Knowles Electronics Manikin for Auditory Research, т.е. манекен Knowles Electronics для слуховых исследований) или с помощью специального "цифрового уха" (digital ear), разработанного в лаборатории Sensaura, располагаемого на голове манекена. Понятно, что измеряется именно HRIR, а значение HRTF получается путем преобразования Фурье. На голове манекена располагаются микрофоны, закрепленные в его ушах. Звуки воспроизводятся через акустические колонки, расположенные вокруг манекена и происходит запись того, что слышит каждое "ухо".
 HRTF представляет собой необычайно сложную функцию с четырьмя переменными: три пространственных координаты и частота. При использовании сферических координат для определения расстояния до источников звука больших, чем один метр, считается, что источники звука находятся в дальнем поле (far field) и значение HRTF уменьшается обратно пропорционально расстоянию. Большинство измерений HRTF производится именно в дальнем поле, что существенным образом упрощает HRTF до функции азимута (azimuth), высоты (elevation) и частоты (frequency), т.е. происходит упрощение, за счет избавления от четвертой переменной. Затем при записи используются полученные значения измерений и в результате, при проигрывании звук (например, оркестра) воспроизводится с таким же пространственным расположением, как и при естественном прослушивании. Техника HRTF используется уже несколько десятков лет для обеспечения высокого качества стерео записей. Лучшие результаты получаются при прослушивании записей одним слушателем в наушниках.
HRTF представляет собой необычайно сложную функцию с четырьмя переменными: три пространственных координаты и частота. При использовании сферических координат для определения расстояния до источников звука больших, чем один метр, считается, что источники звука находятся в дальнем поле (far field) и значение HRTF уменьшается обратно пропорционально расстоянию. Большинство измерений HRTF производится именно в дальнем поле, что существенным образом упрощает HRTF до функции азимута (azimuth), высоты (elevation) и частоты (frequency), т.е. происходит упрощение, за счет избавления от четвертой переменной. Затем при записи используются полученные значения измерений и в результате, при проигрывании звук (например, оркестра) воспроизводится с таким же пространственным расположением, как и при естественном прослушивании. Техника HRTF используется уже несколько десятков лет для обеспечения высокого качества стерео записей. Лучшие результаты получаются при прослушивании записей одним слушателем в наушниках.
Наушники, конечно, упрощают решение проблемы доставки одного звука к одному уху и другого звука к другому уху. Тем не менее, использование наушников имеет и недостатки. Например:
· Многие люди просто не любят использовать наушники. Даже легкие беспроводные наушники могут быть обременительны. Наушники, обеспечивающие наилучшую акустику, могут быть чрезвычайно неудобными при длительном прослушивании.
· Наушники могут иметь провалы и пики в своих частотных характеристиках, которые соответствуют характеристикам ушной раковины. Если такого соответствия нет, то восприятие звука, источник которого находится в вертикальной плоскости, может быть ухудшено. Иначе говоря, мы будем слышать преимущественно только звук, источники которого находится в горизонтальной плоскости.
· При прослушивании в наушниках, создается ощущение, что источник звука находится очень близко. И действительно, физический источник звука находится очень близко к уху, поэтому необходимая компенсация для избавления от акустических сигналов влияющих на определение местоположения физических источников звука зависит от расположения самих наушников.
Использование акустических колонок позволяет обойти большинство из этих проблем, но при этом не совсем понятно, как можно использовать колонки для воспроизведения бинаурального звука (т.е. звука, предназначенного для прослушивания в наушниках, когда часть сигнала предназначена для одного уха, а другая часть для другого уха). Как только мы подключим вместо наушников колонки, наше правое ухо начнет слышать не только звук, предназначенный для него, но и часть звука, предназначенную для левого уха. Одним из решений такой проблемы является использование техники cross-talk-cancelled stereo или transaural stereo, чаще называемой просто алгоритм crosstalk cancellation (для краткости CC).
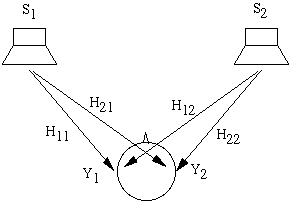 Идея CC просто выражается в терминах частот. На схемы выше сигналы S1 иS2 воспроизводятся колонками. Сигнал Y1 достигающий левого уха представляет собой смесь из S1 и "crosstalk" (части) сигнала S2. Чтобы быть более точными, Y1=H11 S1 + H12 S2, где H11 является HRTF между левой колонкой и левым ухом, а H12 это HRTF между правой колонкой и левым ухом. Аналогично Y2=H21 S1 + H22 S2. Если мы решим использовать наушники, то мы явно будем знать искомые сигналы Y1 и Y2 воспринимаемые ушами. Проблема в том, что необходимо правильно определить сигналы S1 и S2, чтобы получить искомый результат. Математически для этого просто надо обратить уравнение:
Идея CC просто выражается в терминах частот. На схемы выше сигналы S1 иS2 воспроизводятся колонками. Сигнал Y1 достигающий левого уха представляет собой смесь из S1 и "crosstalk" (части) сигнала S2. Чтобы быть более точными, Y1=H11 S1 + H12 S2, где H11 является HRTF между левой колонкой и левым ухом, а H12 это HRTF между правой колонкой и левым ухом. Аналогично Y2=H21 S1 + H22 S2. Если мы решим использовать наушники, то мы явно будем знать искомые сигналы Y1 и Y2 воспринимаемые ушами. Проблема в том, что необходимо правильно определить сигналы S1 и S2, чтобы получить искомый результат. Математически для этого просто надо обратить уравнение: