Состав и ресурсы интернетРефераты >> Программирование и компьютеры >> Состав и ресурсы интернет
Гиперссылки.
Отличительной особенностью среды World Wide Web является наличие средств перехода от одного документа к другому, тематически с ним связанному, без явного указания адреса. Связь между документами осуществляется при помощи гипертекстовых ссылок (или просто гиперссылок). Гиперссылка – это выделенный фрагмент документа (текст или иллюстрация), с которым ассоциирован адрес другого Web-документа. При использовании гиперссылки (обычно для этого требуется навести на неё указатель мыши и один раз щёлкнуть) происходит переход по гиперссылке – открытие Web-страницы, на которую указывает ссылка. Механизм гиперссылок позволяет организовать тематическое путешествие по World Wide Web без использования (и даже знания) адресов конкретных страниц.
Адресация документов.
Для записи адресов документов Интернета (Web-страниц) используется форма, называемая адресом URL. Адрес URL содержит указания на прикладной протокол передачи, адрес компьютера и путь поиска документа на этом компьютере. Адрес компьютера состоит из нескольких частей, разделённых точками, например www.amik.ru . Части адреса, расположенные справа, определяют сетевую принадлежность компьютера, а левые элементы указывают на конкретный компьютер данной сети. Преобразование адреса URL в цифровую форму IP-адреса производит служба имён доменов (Domain Name Service, DNS). В качестве разделителя в пути поиска документа Интернета всегда используется символ косой черты.
Средства просмотра Web.
Документы Интернета предназначены для отображения в электронной форме, причём автор документа не знает, каковы возможности компьютера, на котором документ будет отображаться. Поэтому язык HTML обеспечивает не столько форматирование документа, сколько описание его логической структуры. Форматирование и отображение документа на конкретном компьютере производится специальной программой – браузером (от английского слова browser).
Основные функции браузеров:
- установление связи с Web-сервером, на котором хранится документ, и загрузка всех компонентов комбинированного документа;
- интерпретация тегов языка HTML, форматирование и отображение Web-страницы в соответствии с возможностями компьютера, на котором браузер работает;
- предоставление средств для отображения мультимедийных и других объектов, входящих в состав Web-страниц, а также механизма расширения, позволяющего настраивать программу на работу с новыми типами объектов;
- обеспечение автоматизации поиска Web-страниц и упрощение доступа к Web-страницам, посещавшимся ранее;
- предоставление доступа к встроенным или автономным средствам для работы с другими службами Интернета.
Поисковые машины.
Сеть Интернет растёт очень быстрыми темпами, и найти нужную информацию среди десятков миллионов документов (web-страниц, файлов и др.) становится всё сложнее. Для поиска информации используются специальные поисковые сервера, которые содержат более или менее полную, но постоянно обновляемую информацию о Web-страницах, файлах и других документах, хранящихся на десятках миллионов серверов Интернет.
Различные поисковые сервера могут использовать различные поисковые механизмы (search engine) поиска, хранения и предоставления пользователю информации. Однако общим является то, что к моменту запроса пользователя, вся информация о документах Интернет в компактном виде хранится в базе данных поискового сервера.
Имеющиеся поисковые системы можно условно разделять на три группы::
- Справочники (тематические каталоги) Интернет.
- Поисковые системы общего назначения (индексные).
- Специализированные поисковые системы.
Справочник Интернет является аналогом тематического указателя в библиотеке: он позволяет вам найти наиболее значимые WWW-документы по заданной теме. Примером таких систем является поисковый сервер Yahoo:
http://www.yahoo.com
Поисковые системы общего назначения позволяют находить документы в WWW по ключевым словам. Принцип, на котором основано большинство таких систем, состоит в том, что специальные программы-роботы автоматически обходят WWW-серверы, читают и индексируют все встречающиеся документы, выделяя при этом ключевые слова, относящиеся к данному документу, и запоминая их вместе с URL этого документа в базе данных. Большинство поисковых систем разрешают также автору новой Web-страницы самому внести информацию в базу данных.
Обращаясь к такой поисковой системе, мы выводим одно или несколько ключевых слов, которые, по нашему мнению, могли бы вывести нас на интересующую информацию, и отправляем запрос одним нажатием мышки на экранной кнопке, обычно называемой Поиск (Submit). Через несколько секунд поисковая система вернёт нам список URL-документов, в которых были найдены указанные нами ключевые слова. Примером такой поисковой системы является Rambler:
http://www.rambler.ru
Специализированные поисковые системы позволяют нам находить информацию, по конкретным наукам, специализациям, по интересующим вас областях. Пример такой поисковой системы является http://www.avatarsearch.com/ . Поисковая система AvatarSearch предназначена для людей, которые интересуются вопросами оккультизма и мистики. Ссылки на страницы, авторы которых особо преуспели в освещении данной тематики, получают специальный знак отличия от создателей этого сайта.
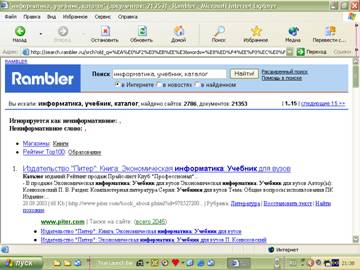
Рис.1 Интерфейс Rambler
 Так как информация в Интернет постоянно меняется (создаются новые документы, удаляются старые и т.д.) поисковые роботы не всегда успевают отследить все эти изменения. Информация, хранящаяся в базе данных поискового сервера, может отличаться от реального состояния Интернет, и поэтому иногда пользователь может получить ссылку на уже не существующий или перемещённый документ.
Так как информация в Интернет постоянно меняется (создаются новые документы, удаляются старые и т.д.) поисковые роботы не всегда успевают отследить все эти изменения. Информация, хранящаяся в базе данных поискового сервера, может отличаться от реального состояния Интернет, и поэтому иногда пользователь может получить ссылку на уже не существующий или перемещённый документ.
Интерфейс поисковых серверов обычно примерно одинаков, и
Рис.2 Результаты поиска
 поэтому рассмотрим его на примере российского поискового сервера RAMBLER (http://www.rambler.ru).
поэтому рассмотрим его на примере российского поискового сервера RAMBLER (http://www.rambler.ru).
Начальная страница поисковой системы содержит список разделов, уточняющих область поиск, и поле поиска. В поле поиска пользователь может ввести ключевые слова для поиска документа, то есть слова, которые, по мнению пользователя, позволят идентифицировать документ.
Поставим задачу найти сведения об учебниках по информатике. Однако перед тем, как ввести ключевые слова в поле поиска, целесообразно сузить область поиска, выбрав из списка разделов категорию Образование.
В качестве ключевых выберем слова: информатика, учебник, каталог – и введём их в поле поиска. В результате мы получим явно избыточную информацию, перечень почти из 90 тысяч документов, так как слово информатика содержится в 519249 документах, слово учебник – в 885564 документах и слово каталог – в 12622835.