Создание исследовательского прототипа системы идентификации табличных данныхРефераты >> Программирование и компьютеры >> Создание исследовательского прототипа системы идентификации табличных данных
Содержание
1. Введение.
2. Постановка задачи.
3. Структура системы идентификации.
3.1 Блок предварительной обработки.
3.2 Блок идентификации.
4. Алгоритм сравнения двух слов.
5. Представление данных в иерархической структуре.
6. Программная реализация.
6.1 Объекты программирования.
6.2 Описание интерфейса.
7. Заключение.
8. Список литературы.
9. Приложение.
1 Введение.
В последние годы в нашей стране все больше и больше фирм и организаций приобретают вычислительные машины с целью использования их в своем бизнесе. Персональные вычислительные машины стали неотъемлемой частью нашего быта. Они очень удобны для выполнения различных повседневных задач: составления отчетов и графиков работы, ведение бухгалтерии, планирования и оптимизации производства.
Вместе с развитием вычислительной техники развивается также и область производства прикладных и системных программ, без которых компьютеры не представляют никакого интереса для людей непосвященных в программирование. На сегодняшний день много фирм – производителей программной продукции производят универсальные пакеты прикладных и системных программ для широкого спектра повседневных задач. В основном эти пакеты предназначены для решения, каких – то общих задач: составления отчетов, ведения календарей, редактирования различного рода текстов и графической информации. Существуют также пакеты программ для создания различного рода приложений к разным операционным системам.
Целью моей работы являлось создание программы, позволяющей идентифицировать с целью дальнейшего анализа нестандартизованные табличные данные одной предметной области. Можно говорить о тех предметных областях, в которых описание объекта недостаточно формализовано для непосредственного сравнения, но достаточно формализовано для того, чтоб не строить семантическую модель предметной области.
Такая программа была бы полезна, например, для торговой фирмы с большой товарной номенклатурой и множеством поставщиков, позволяя автоматически выбирать оптимального поставщика для каждой товарной позиции.
Для решения поставленной задачи в качестве среды разработки было принято решение использовать C++ Builder 5 поскольку, на мой взгляд, он дает больше свободы творчеству, чем другие средства, предоставляющие те же возможности.
Ниже приведена постановка задачи. Рассмотрена структура системы идентификации. Далее описан алгоритм сравнения данных. А также рассмотрена возможность представления входных данных в виде иерархической структуры, что позволяет ускорить процесс, проводя идентификацию сначала для узлов дерева, а затем для листьев совпавших узлов. Затем приведено краткое описание интерфейса приложения и основных объектов программирования.
2. Постановка Задачи.
Основная проблема рассмотренная в моей работе заключается в том, что табличные данные поступают от разных источников. Это приводит к тому, что описание одного и того же объекта может иметь несколько допустимых представлений. Все они должны идентифицироваться как один объект. Существенным аспектом в идентификации является выбор признаков в процессе предварительной обработки исходных данных. Другим важным аспектом является процесс решения, основанный на использовании этих признаков и обеспечивающих получение результатов идентификации.
Для первого аспекта важным является следующее: какие входные данные можно считать уместными, и какая обработка исходных данных приводит к получению признаков действительно позволяющих проводить идентификацию.
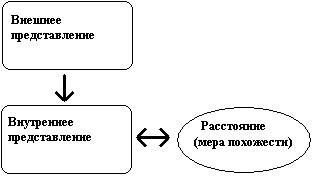 |
Общая схема процесса.
Будем считать, что имеется база данных с иерархической структурой содержащая описания объектов в одном из представлений. Любой из источников можно взять за такую базу данных. В таком случае задача сведется к идентификации входящих описаний объектов на множестве описаний нашей базы данных или, возможно, принятия решения об отказе идентификации. Для входящего описания достаточно будет вычислить значения меры похожести в паре с каждым описанием из нашей базы данных и, выбрав из них наибольшее значение, вынести решение об идентификации или отказе от нее. Не исключено, что такой перебор всех описаний может занять продолжительное время.
Выделим основные задачи этапа предварительной обработки данных и этапа идентификации.
Этап предварительной обработки.
· Выбор и построение процедур фильтрации данных.
· Задача формирования признаков и выбор данных для их формирования.
Этап идентификации.
· Построение адекватного алгоритма, который вычисляет меру похожести двух описаний.
· Задача уменьшения перебора описаний.
Идеи и методы решения этих задач подробнее рассмотрены ниже.
3. Структура системы идентификации.
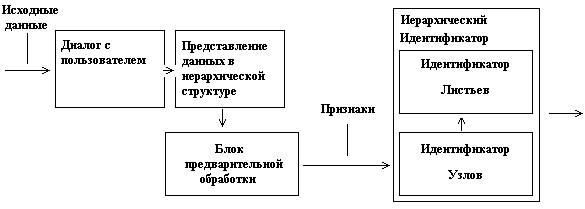 |
При настройке системы для предметной области формируется справочник признаков и справочник единиц измерения числовых признаков. Каждый элемент справочника признаков содержит кроме уникального кода и названия содержит информацию о типе признака («строковый», «числовой») и для числового признака ссылку на соответствующий элемент в справочнике единиц измерения. Справочник единиц измерения содержит уникальный код, название единицы измерения и возможно специальную аббревиатуру.
В некоторых ситуациях невозможно или трудно обеспечить полностью автоматическую идентификацию. Выходом из положения может явиться участие человека на отдельных этапах. Работа над программой продолжается, но пока требуется участие пользователя.
На этапе диалога с пользователем требуется сопоставить столбцам таблицы элементы справочника признаков, в каждом столбце может быть несколько числовых признаков и один текстовый. Для некоторых столбцов может не быть соответствующего элемента в справочнике признаков. Эти столбцы сразу исключаются из дальнейшего рассмотрения. В каждой позиции данные из разных столбцов по отдельности поступают на вход блока предварительной обработки.
Теперь данные представляются в виде дерева (об этом будет сказано ниже). Записывается два файла: файл-заголовок, содержащий информацию о соответствии столбцам признаков и файл данных в виде дерева, где узлам соответствуют группы объектов, а листьям - объекты.