Системное автоматизированное проектирование. ЛекцииРефераты >> Программирование и компьютеры >> Системное автоматизированное проектирование. Лекции
общенной экспертной системы.
Лингвистический процессор осуществляет связь остальных компонент с пользователем или экспертом на алгоритмическом языке.
Подсистема логического вывода обеспечивает построение той или схемы рассуждения.
База знаний предназначена для хранения и обработки знаний, представленных логическими, продукционными либо семантическими моделями.
Подсистема ревизии знаний позволяет пользователю либо эксперту вмешиваться в процесс подготовки принятия решения за счет объяснения (отображения) промежуточных действий в системе.
Рабочая память обеспечивает хранение промежуточных данных и их обмен между компонентами системы.
В некоторых работах по искусственному интеллекту можно встретить несколько другое представление обобщенной экспертной системы, причем, принципиальным отличием может явиться наличие в структуре подсистемы приобретения и интерпретации знаний. Однако в таких системах, как EURISKO, роль такой подсистемы выполняет подсистема логического вывода совместно с подсистемой ревизии знаний, а в системе MYSIN ее невозможно выделить как отдельное программное средство. В системах, построенных по технологии "prototyping" - ИНТЕРЭКСПЕРТ (GURU), ЭКСПЕРТИЗА, т.е. на основе оболочек, также трудно выделить такой программный модуль, который обеспечивал бы приобретение знаний.
Рассмотрим подробнее структурные компоненты экспертной системы.
КОМПОНЕНТЫ ЭКСПЕРНОЙ СИСТЕМЫ
ЛИНГВИСТИЧЕСКИЙ ПРОЦЕССОР
Лингвистический процессор обеспечивает взаимодействие пользователя либо эксперта с программно-аппаратной частью экспертной системы путем преобразования (трансляции, конвертирования, интерпретации) предложений на проблемно-ориентированном (чаще на естественном) языке в предложения на внутреннем языке (метаязыке) и наоборот.
На рис.1 не показано, что в этих преобразованиях участвует база знаний, поскольку во многих экспертных системах лингвистические процессоры реализуются отдельным модулем, имеющим программно-аппаратный вид.
Достаточно общее название этой структурной единицы позволяет рассматривать под этим названием самые различные программные и программно-аппаратные реализации. Они независимы от способа кодирования сообщения: речевой ввод, ввод с алфавитно-цифровой клавиатуры, с сенсорного устройства и т.д.
В любом случае считается, что входными данными лингвистического процессора являются цепочки символов, представленных во внутреннем коде системы, а выходными - либо цепочки, синтезированные на языке деловой прозы для человека, либо цепочки на метаязыке системы.
Преобразование лексических единиц на естественном языке возможно в процедурной, декларативной или смешанной форме. Для декларативной формы характерно существование некоторого словаря и морфологический анализ сводится к сопоставлению соответствующих лексем.
Процедурный способ морфологического анализа основывается на определении последовательности операций, которые необходимо осуществить для определения значений морфологических параметров. При этом под морфологией понимается система правил порождения слов.
База знаний, над которой строится лингвистический процессор, содержит словарь, множество фильтрующих процедур и семантическую сеть. С помощью словаря осуществляется представление знаний о словах (лексемах).
Фильтрующие процедуры реализуют правила анализа и синтеза лексем, а семантические сети кодируют смысловые структуры предметной области.
Структура основной части лингвистического процессора и взаимодействие его элементов условно представлены на рис.2.
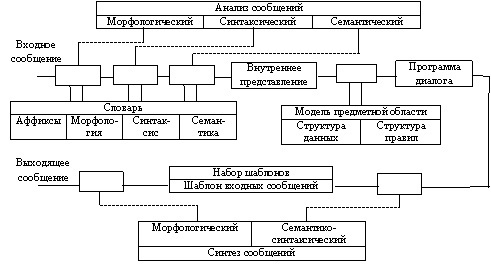 Рис.2. Структура лингвистического процессора
Рис.2. Структура лингвистического процессора
В процессе анализа сообщения пользователя выделяются корни слов, идентифицируется совокупность корней по словарю, хранящемуся в рабочей памяти, проводится морфологический разбор и после семантического разбора порождается сообщение на метаязыке системы.
При синтезе сообщения чаще всего используется множество формальных шаблонов, которые выбираются в соответствии с семантикой сообщения и заполняются в соответствии с его морфологией и синтаксисом.
Лингвистический процессор систем ИНТЕРЭКСПЕРТ, ЭКСПЕРТИЗА позволяет осуществлять связь на естественном языке и рассчитан на распознавание до 500 слов и команд. Процесс формирования интерфейса реализуется с помощью меню. Оно предлагается пользователю всякий раз, когда введенное предложение на естественном языке содержит слова, не содержаржащиеся в словаре процессора.
Меню предлагает пользователю варианты типа:
- "временное изменение",
- "постоянное изменение",
- "более длинная фраза",
- "игнорировать слово" ,
- "снять запрос".
В первом режиме составляется временное определение, которое хранится до следующего запроса. При этом нераспознанное слово автоматически приводится в семантическое соответствие с синонимом из словаря в течение текущего запроса.
экспертной системе позволяет со временем снимать разграничения в функциях эксперта и пользователя.
Возможности наиболее распространенных в настоящее время экспертных систем в области ревизии знаний пока ограничены. В основном, пользователю объясняют причины запросов и раскрывают Во втором режиме проводится постоянное доопределение словаря соответствующим синонимом.
В третьем режиме синонимы вводятся уже не для отдельных слов, а для словосочетаний.
Четвертый режим позволяет пользователю понизить избыточность в сообщении, если какое-то слово в фразе, кодирующей запрос, нераспознано процессором, а пятый позволяет прекратить бесплодные попытки разъяснить принципиально неопознанную фразу запроса.
Лингвистический процессор ИНТЕРЭКСПОРТ расширен на область графического представления данных в виде таблиц и графиков.
ПОДСИСТЕМА ЛОГИЧЕСКОГО ВЫВОДА
Подсистема логического вывода, предназначенная для генерации рекомендаций по решению прикладной задачи на основе информации, находящейся в базе знаний, строится на основе теории машины Поста.
На структурной схеме, показанной на рис.3, определены связи между компонентами этой подсистемы в соответствии с принципами функционирования машины Поста. Согласно наименованию, подсистема порождает правило на основе импликации вида:
Ri : Ii Þ Ri’, где Ri - правило продукции, извлекаемое из базы знаний, Ii - условие применения правила Ri,
R’ - порождаемое правило, которое может быть помещено либо не помещено в базу знаний.
 Рис.3. Структура и принцип функционирования интерпретатора
Рис.3. Структура и принцип функционирования интерпретатора
В процессе решения той или иной задачи в подсистеме производится интерпретация (означивание) того или иного правила и выполнение действий, определяемых этим правилом. Выбор (идентификация) того или иного правила основан на сопоставлении условий Ii и в общем случае приводит к нескольким правилам одновременно. При этом возможно порождение порождается конфликтного набора.