Информационные технологии в управленииРефераты >> Программирование и компьютеры >> Информационные технологии в управлении
Если данные состоят из коротких, простых полей фиксированной длины (имя, адрес, баланс банковского счета), то лучшим решением будет применение реляционной базы данных. Если, однако, данные содержат вложенную структуру, динамически изменяемый размер, определяемые пользователем произвольные структуры (мультимедиа, например), представление их в табличной форме будет, как минимум, непростым. В то же время в ООСУБД каждая определенная пользователем структура – это объект, непосредственно управляемый базой данных.
В РСУБД связи управляются пользователем, создающим внешние ключи. Затем для обнаружения связей динамически во время выполнения система просматривает две (или больше) таблицы, сравнивая внешние ключи до достижения соответствия. Этот процесс, называемый объединением (join), является слабой стороной реляционной технологии. Более двух или трех уровней объединений – сигнал, чтобы искать лучшее решение. В ООСУБД пользователь просто объявляет связь, и СУБД автоматически генерирует методы управления, динамически создавая, удаляя и пересекая связи. Ссылки при этом прямые, нет необходимости в просмотре и сравнении или даже поиске индекса, который может сильно сказаться на производительности. Таким образом, применение объектной модели предпочтительнее для баз данных с большим количеством сложных связей: перекрестных ссылок, ссылок, связывающих несколько объектов с несколькими (many-to-many relationships) двунаправленными ссылками.
В отличие от реляционных, ООСУБД полностью поддерживают объектно-ориентированные языки программирования. Разработчики, применяющие С++ или Smalltalk, имеют дело с одним набором правил (позволяющих использовать такие преимущества объектной технологии, как наследование, инкапсуляция и полиморфизм). Разработчик не должен прибегать к трансляции объектной модели в реляционную и обратно. Прикладные программы обращаются и функционируют с объектами, сохраненными в базе данных, которая использует стандартную объектно-ориентированную семантику языка и операции. Напротив, реляционная база данных требует, чтобы разработчик транслировал объектную модель к поддерживаемой модели данных и включил подпрограммы, чтобы обеспечить это отображение во время выполнения. Следствием являются дополнительные усилия при разработке и уменьшение эффективности.
И, наконец, ООСУБД подходят (опять же без трансляций между объектной и реляционной моделями) для организации распределенных вычислений. Традиционные базы данных (в том числе и реляционные и некоторые объектные) построены вокруг центрального сервера, выполняющего все операции над базой. По существу, эта модель мало отличается от мэйнфреймовой организации 60‑х годов с центральной ЭВМ – мэйнфреймом (mainframe), выполняющей все вычисления, и пассивных терминалов. Такая архитектура имеет ряд недостатков, главным из которых является вопрос масштабируемости. В настоящее время рабочие станции (клиенты) имеют вычислительную мощность порядка 30 ‑ 50 % мощности сервера базы данных, то есть большая часть вычислительных ресурсов распределена среди клиентов. Поэтому все больше приложений, и в первую очередь базы данных и средства принятия решений, работают в распределенных средах, в которых объекты (объектные программные компоненты) распределены по многим рабочим станциям и серверам и где любой пользователь может получить доступ к любому объекту. Благодаря стандартам межкомпонентного взаимодействия (об этом позже) все эти фрагменты кода комбинируются друг с другом независимо от аппаратного, программного обеспечения, операционных систем, сетей, компиляторов, языков программирования, различных средств организации запросов и формирования отчетов и динамически изменяются при манипулировании объектами без потери работоспособности.
4.2 Спорные моменты технологии.
Все ООСУБД по определению поддерживают сохранение и разделение объектов. Но, когда дело доходит до практической разработки приложений на разных ООСУБД, проявляется множество отличий в реализации поддержки трех характеристик:
· Целостность;
· Масштабируемость;
· Отказоустойчивость.
Отметим, что ООБД не требуют многих из тех внутренних функций и механизмов, которые столь привычны и необходимы в реляционных БД. Например, при небольшом числе пользователей, длинных транзакциях и незначительной загрузке сервера объектные СУБД не нуждаются в поддержке сложных механизмов резервного копирования/восстановления (исторически сложилось так, что первые ООБД проектировались для поддержки небольших рабочих групп – порядка десяти человек – и не были приспособлены для обслуживания сотен пользователей). Тем не менее технология БД определенно созрела для крупных проектов.
Для иллюстрации первой категории рассмотрим механизм кэширования объектов. Большинство объектных СУБД помещают код приложения непосредственно в то же адресное пространство, где работает сама СУБД. Благодаря этому достигается повышение производительности часто в 10‑100 раз по сравнению с раздельными адресными пространствами. Но при такой модели объект с ошибкой может повредить объекты и разрушить базу данных.
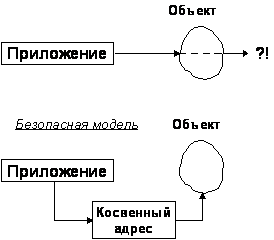
Существуют два подхода к организации реакции СУБД для предотвращения потери данных. Большинство систем передают приложению указатели на объекты, и рано или поздно такие указатели обязательно становятся неверными. Так, они всегда неправильны после перехода объекта к другому пользователю (например, после перемещения на другой сервер). Если программист, разрабатывающий приложение, пунктуален, то ошибки не возникает. Если же приложение попытается применить указатель в неподходящий для этого момент, то в лучшем случае произойдет крах системы, в худшем – будет утеряна информация в середине другого объекта и нарушится целостность базы данных.
Есть метод, лучший, чем использование прямых указателей (Рисунок 3). СУБД добавляет дополнительный указатель и при необходимости, если объект перемещается, система может автоматически разрешить ситуацию (перезагрузить, если это необходимо, объект) без возникновения конфликтной ситуации.
Существует еще одна причина для применения косвенной адресации: благодаря этому можно отслеживать частоту вызовов объектов для организации эффективного механизма свопинга.
Это необходимо для реализации уже второго необходимого свойства баз данных – масштабируемости. Опять следует упомянуть организацию распределенных компонентов. Классическая схема клиент-сервер, где основная нагрузка приходится на клиента (такая архитектура называется еще “толстый клиент-тонкий сервер”), лучше справляется с этой задачей, чем мэйнфреймовая структура, однако ее все равно нельзя масштабировать до уровня предприятия. Благодаря многозвенной архитектуре клиент-сервер (N-Tier architecture) происходит равномерное распределение вычислительной нагрузки между сервером и конечным пользователем. Нагрузка распределяется по трем и более звеньям, обеспечивающим дополнительную вычислительную мощность. К чему же еще ведет такая практика? “Архитектура клиент-сервер, еще совсем недавно считавшаяся сложной средой, постепенно превратилась в исключительно сложную среду. Почему? Благодаря ускоренному переходу к использованию систем клиент-сервер нескольких звеньев” (PC Magazine). Разработчикам приходится расплачиваться дополнительными сложностями, большими затратами времени и множеством проблем, связанных с интеграцией. Оставим очередное упоминание распределенных компонентов на этой не лишенной оптимизма ноте.
|
Рисунок 3 Прямая и косвенная адресации. |