Обзор архитектуры процессоров Pentium фирмы IntelРефераты >> Программирование и компьютеры >> Обзор архитектуры процессоров Pentium фирмы Intel
 |
Процессор PentiumMMX – P55C.
В 1996 году Intel разработала процессор с новым расширением, ориентированным на применение в мультимедиа, 2D и 3D графику. Итак, P55C это:
1. Увеличенные кэши команд и данных – по 16К каждый.
2. Расширенная CMOS (E-CMOS) технология позволила расположить на кристалле 4.5 миллионов транзисторов.
3. Увеличено количество ступеней конвейера.
4. Улучшен способ предсказания ветвлений (он был позаимствован у Pentium PRO).
5. Количество буферов записи увеличено вдвое, их теперь четыре.
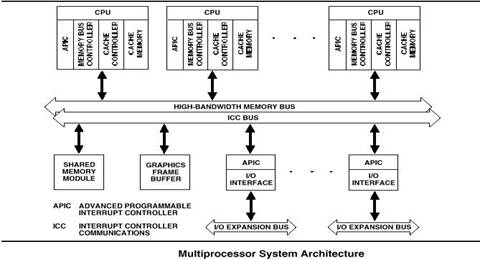
6. Для мультипроцессорной системы реализован только режим SMP, FRC исключён.
7. И, наконец, самое интересное! На кристалле расположен новый блок – блок MMX (Multi Media Extention), который позволяет обрабатывать целочисленные данные (определённого типа – нового) методом SIMD (Single Instruction Multiple Data) – одна инструкция параллельно обрабатывает несколько данных. Для реализации блока MMX были введены:
A. восемь дополнительных 64-битных регистра (ММ0 .ММ7)
B.
 |
C. 57 новых инструкций для одновременной обработки нескольких единиц данных одновременно.
На самом деле, регистры MMX физически расположены в стеке регистров FPU, так что новых регистров этот процессор не предоставляет, и чередование использования программой инструкций FPU и MMX приводит к снижению эффективности работы, связанному с необходимостью пересылок данных из стека в память и обратно. В принципе, эффективность MMX вызывает некоторые сомнения, так как те функции, для которых они целесообразны, с неоспоримо большим успехом выполняются графическими акселераторами, которые уже стали обыденными J. К тому же для использования новых команд необходима перекомпиляция ПО. Можно предположить, что введение MMX является первой ступенью в маниакальном стремлении Intel перенести всю работу в ПК на плечи центрального процессора, получившем дальнейшее распространение в Katmai (Pentium III) в виде новых KNI (SSE)-команд (вспомним рекламу: Pentium III – новые возможности Internet, хе-хе).
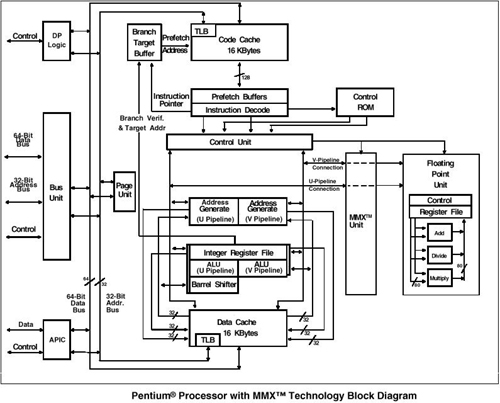
Блок-диаграмму процессора P55C можно увидеть здесь:
 |
Процессор P6 – PentiumPRO.
Революционная вещь в своём роде. Выпущен где-то в районе 1995 года. Первые экземпляры были выполнены по 0.6 мкм BiCMOS-технологии. Тройная суперскалярная архитектура (конвейер имеет 12 уровней и поддерживает динамическое выполнение инструкций) – возможно выполнение 3-х команд за такт.
1. Шина адреса расширена до 36 разрядов, соответственно максимальный размер адресуемой памяти составляет 64 Гб. Разрядность шины данных – 64 бита.
2. Кэши. Кэш L1 состоит, как и в предыдущих процессорах, из кэша команд + кэша данных, оба по 8К. На кристалле (!) интегрирован синхронный кэш второго уровня L2 объёмом 256К, 512К либо 1024К. В поздних версиях его размер достигает 2М. Кэш L2 подключен к внутренней шине и работает на частоте ядра.
3. В процессорах этой серии применяется технология динамического исполнения, т.е. внутри процессора инструкции могут выполняться не в том порядке, который предполагает программный код. При этом команды, не зависящие от результатов предыдущих операций, могут быть выполнены в изменённом порядке, но последовательность выгрузки результатов в память и порты будет соответствовать исходному программному коду. ( Почему это тем не менее машина фон-Неймана ? А потому, что подтверждения выставляются в том порядке, который предполагает программный код). Динамическое исполнение включает в себя:
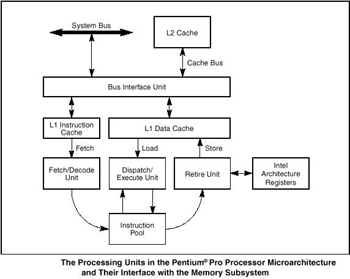
· Глубокий прогноз ветвлений, который позволяет декодировать инструкции за пределами ветвлений, чтобы поддерживать конвейер в максимально полном состоянии (не давать ему простаивать). Этим занимается модуль Fetch/Decode (см. рисунок), использующий оптимизированные алгоритмы прогноза.
· Динамический анализ потока данных. Модуль Dispatch/Execute может одновременно проверить несколько инструкций и выполнить их в том порядке, который наиболее оптимален. Он выполняет все доступные инструкции, записывает их в пул инструкций, и сохраняет результаты во временных регистрах; после чего устройство Retire просматривает пул инструкций с целью выделить те из них, результат выполнения которых уже не зависит от выполнения других инструкций. Когда такие завершённые инструкции обнаруживаются, Retire Unit отправляет результаты выполнения этих инструкций в память и/или в регитры общего назначения и регистры данных FPU, в порядке следования, предписанным программой.
· Интеллектуальное выполнение. Это свойство выражается в возможности процессора выполнять команды опережая программный счётчик, но в то же время позволяет получать результаты, соответствующие выполнению команд в исходной последовательности.
 |
4. В Pentium PRO применена архитектура двойной независимой шины (Dual Independent Bus). Одна шина – системная – служит для общения ядра с основной памятью и интерфейсными устройствами, другая – внутренняя – предназначена исключительно для обмена со вторичным кэшем. Применение динамического исполнения резко повышает частоту запросов процессорного ядра к шине за данными памяти и инструкциями, поскольку ядро одновременно обрабатывает нескольео инструкций. Для обхода узкого места – внешней шины – кристалл процессорного ядра и использует технологию двойной независимой шины. Значительный объём вторичного кэша позволяет удовлетворять большинство запросов к памяти сугубо локально, при этом коэффициент загрузки шины достигает 90% (необходимо заметить, что обмен данными по внутренней шине происходит значительно быстрее, чем по внешней, так как кэш L2 работает на частоте ядра, то есть порядка 200 МГц). Вторая шина процессорного кристалла выходит на внешние выводы микросхемы, она и является системной шиной процессора Pentium PRO. Эта шина работает на внешней частоте (66,6 МГц) независимо от внутренней шины. Загрузка процессором внешней шины для обычных рядовых применений составляет порядка 10% от её пропускной способности, а для серверных применений может достигать 60% при четырёхпроцессорной конфигурации. Таким образом, ограниченная пропускная способность внешней шины (533 Мбайт/с в пике пакетной передачи) перестаёт сильно сдерживать производительность процессора. Снижение нагрузки на внешнюю шину позволяет эффективно использовать многопроцессорную архитектуру.