Микропроцессорные системы. КнигаРефераты >> Программирование и компьютеры >> Микропроцессорные системы. Книга
Другим классом суперЭВМ, тесно связанным с матричными процессорами, является подкласс ММПС типа SIMD/MIMD (суперЭВМ PASM, NonVon, DADO). На самом низшем уровне они имеют архитектуру типа SIMD, но, как правило, не состоят из одноразрядных процессоров. Введение параллелизма типа MIMD как надстройки над параллелизмом типа SIMD существенно расширяет возможности суперЭВМ этого класса.
Обобщенный матричный процессор состоит из скалярной последовательной части и направленного массива процессорных элементов (ПЭ) (рис.5.9).
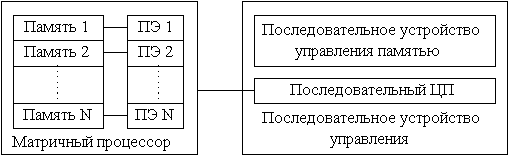
Рис. 5.9. Обобщенный матричный процессор
Внутри матричной ММПС должна осуществляться строгая пошаговая синхронизация. Матричный контроллер передает сигналы управления синхронизацией всем процессорам параллельно. Этот уровень синхронизации используется для обеспечения высокой скорости межпроцессорной коммутации и обмена данными. Для организации межпроцессорных обменов широко используются одно- или двумерные сети.
СуперЭВМ с гиперкубической архитектурой INTEL iPSC-VX являлась одной из первых выпущенных систем этого типа. Её максимальная производительность составляет 424*106 Флопс. Надо отметить, что аналогичные и рассмотренные выше суперЭВМ серии Т фирмы FPS и Connection Machine фирмы Thinking Machines появились значительно позже. В системе iPSC-VX используется стандартный МП 80286, сопроцессор 80287, сопроцессор локальной сети (LAN) 82586, семь последовательных каналов ввода-вывода, динамическое ЗУПВ емкостью 512 Кбайт, которые размещены на печатной плате, выполняющие функции узла гиперкуба (рис. 5.10).
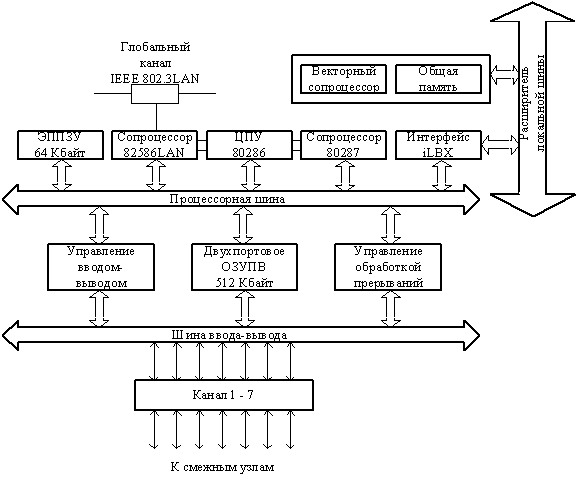
Рис. 5.10. Структура процессорного узла супер-ЭВМ Intel iPSC-VX
С помощью расширителя местной шины iLBX-II к узлу может подключаться дополнительная память. Векторный сопроцессор, расположенный на второй плате узла, повышает его производительность до 100 раз при выполнении операций над 64-разрядными скалярными данными. Система iPSC-VX наращивается группами по 16, 32 или 64 узла.
Управляющий процессор куба (микроЭВМ системы 286/310 фирмы Intel) соединяется с каждым узлом посредством локальной сети IEEE 802.3 и обеспечивает реализацию системного интерфейса, а также системы разработки программных средств на основе операционной системы типа XENIX. Наличие семи каналов связи у каждого узла определяет возможность построения гиперкуба с максимальным числом N=27=:128 узлов. Ядро операционной системы размещается в ЗУПВ и обеспечивает реализацию основных сервисных функций.
Контрольные вопросы
1. Перечислите классы ЭВМ в зависимости от круга решаемых задач.
2. Приведите структуру скалярной и векторной ЭВМ, поясните их основные отличия и особенности работы.
3. Перечислите уровни параллелизма ММПС и основные архитектурные формы ММПС.
4. Поясните взаимосвязь между векторной, параллельной и скалярной производительностью ММПС.
5. Перечислите виды топологий связей процессорных элементов в ММПС.
6. ТРАНСПЬЮТЕРНЫЕ СИСТЕМЫ
Развитие традиционных архитектур ЭВМ с микропрограммным управлением и микропроцессоров привело к появлению сложных ИС с большими наборами команд, что позволило повысить эффективность труда программистов, но значительно усложнило топологию ИС и понизило производительность ЭВМ.
Как альтернатива этому направлению являются компьютеры с сокращенным набором команд (КСНК) или RISС-процессоры, которые превосходят производительность ЭВМ с большими наборами команд, так как благодаря организации их команд последние выполняются за один машинный цикл. Большинство операций в КСНК имеют характер «регистр-регистр», а обращения к основной памяти происходят только для выполнения простых операций загрузки в регистры и занесения в память; смежные же команды преобразуются в последовательность простых, которые выполняются быстрее. Уменьшение количества логических вентилей и объема микропрограммных ПЗУ позволяет существенно снизить размеры МП и их стоимость. На рис. 6.1 приведена структурная схема базовой архитектуры компьютера с сокращенным набором команд.
Блок выборки команд осуществляет опережающую выборку команд из основной памяти или кэша и помещает их в буфер предварительной выборки. Блок реализации команд принимает команды из буфера предварительной выборки и выполняет необходимые операции, после чего помещает результат в один из регистров, подготавливая последующее выполнение операции «регистр – регистр».
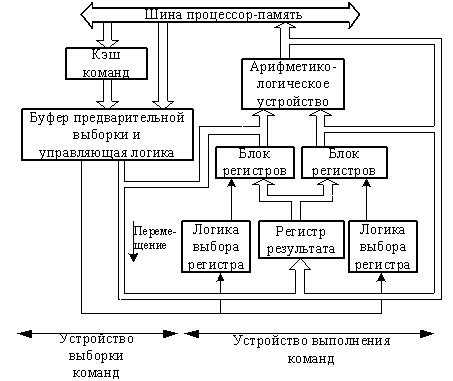
Рис. 6.1. Базовая архитектура КСНК
Команды, выполнявшиеся последними, остаются в кэше, чтобы был обеспечен быстрый доступ к ним при выполнении циклов. Для совмещения во времени действий по выборке, декодированию и выполнению операций используется конвейеризация. При опережающей выборке команд может быть применен метод предугадывания ветвления, так как при выполнении команд условного перехода возможно снижение скорости обработки, когда для выборки следующей команды необходимо сначала выяснить направление перехода.
Типичным представлением КСНК являются транспьютеры, которые предназначены для построения МКМД-структур. Рассмотрим логическую структуру транспьютера на примере типичного представления этого класса МП – транспьютере Inmos T414, структурная схема которого приведена на рис. 6.2.
Транспьютер Т414 представляет собой 32 – разрядный микропроцессор, в состав которого входят центральное процессорное устройство с архитектурой КСНК, внутрикристальное ЗУПВ емкостью 2 Кбайт, четыре быстродействующих последовательных канала связи и таймер с разрешающей способностью 1 мкс. Внутренняя архитектура транспьютера соответствует фон-неймановским принципам, т.е. включает единую шину адресов и данных, связывающих ЦПУ со встроенной и внешней памятью.
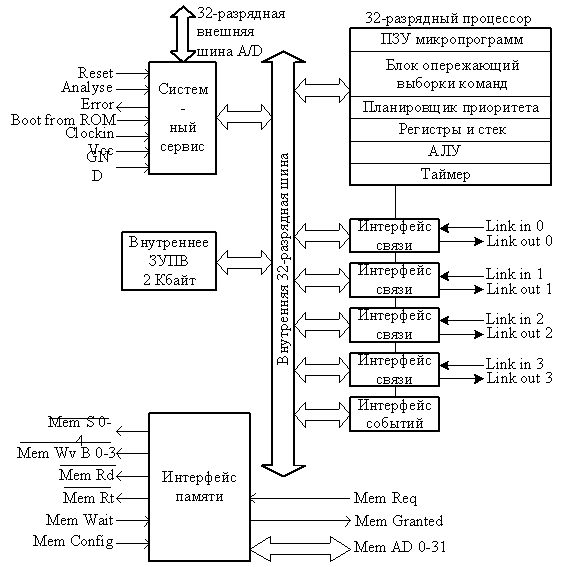
Рис. 6.2. Структура транспьютера Т414
В транспьютере Т414 используются простые 8-битовые базовые команды, но могут быть созданы и многобайтовые. Используемые регистры и способы пересылки данных между ними указываются в команде неявным образом.
Как видно из рис. 6.2, транспьютер Т414 имеет мультиплексируемую 32-разрядную шину внешней памяти с диапазоном физических адресов 4 Гбайт. Дополнительная память может иметь различную конфигурацию, причем возможно включение в ее состав одновременно и быстродействующих, и медленных устройств. Предусмотрены сигналы регистрации динамических ЗУПВ. Скорость пересылки данных по шине внешней памяти может достигать 25 Мбайт/с.
Взаимодействие каждого транспьютера с другими, а также с периферией, осуществляется посредством четырех каналов связи. Для передачи сообщений из внутренней и внекристальной локальной памяти по последовательным каналам применяется механизм блочных ПДП-пересылок. Интерфейсы связи и процессор работают одновременно и потери производительности процессора незначительны. Использование прямых последовательных коммуникационных каналов делает ненужным арбитраж приоритетов и исключает проблемы, связанные с пропускной способностью шин и их перегрузкой при введении в систему новых процессоров.