Расчет квантово-химических параметров ФАВ и определение зависимости структура-активность на примере сульфаниламидов
Одна из интересных особенностей этих методов заключается в том, что они могут иметь дело с многомерными данными, т. е. данными, в которых для представления каждого объекта используется более трех параметров. К тому же этими методами можно анализировать данные, полученные из разных источников, а также данные, связи между которыми имеют разрывный характер. При соответствующем подходе методы распознавания образов дают возможность установить критерий отбора из исходного множества данных тех параметров, которые существенны для описания исследуемых свойств. Далее с помощью этого набора наиболее значимых признаков могут быть получены указания о направлении дальнейших исследований.
1.2.2 Основные понятия методов распознавания образов
Прежде чем начать обсуждение методов распознавания образов, необходимо объяснить, что подразумевается под классификацией объекта или группы объектов. В процессе классификации формируется правило разделения группы объектов на несколько категорий, а при распознавании это классификационное правило используется для отнесения неизвестного объекта к одной из рассматриваемых категорий. Классификационное правило устанавливается в виде некоторой гипотезы, полученной в результате анализа экспериментальных данных. Проверка правильности этой гипотезы проводится путем ее испытания на объектах, не включенных в группу данных, с помощью которых было получено классификационное правило. В случае удачных испытаний гипотеза считается правильной. Процесс классификации заключается не только в выработке классификационного правила и его дальнейшего применения для распознавания. Ниже на простом примере будут продемонстрированы основные особенности задачи распознавания образов.
В качестве примера построения классификационного правила рассмотрим следующую воображаемую задачу. Предположим, что мы хотим автоматизировать процесс идентификации аномальных клеток при анализе крови в клинической лаборатории. Попробуем составить опытный проект оптической воспринимающей системы, способной отличить лейкимические клетки от здоровых на основе оптической проницаемости (рис. 2.1.1). Будем считать, что если прозрачность клетки превосходит некоторый уровень Хо, то она относится к лейкемическим клеткам.
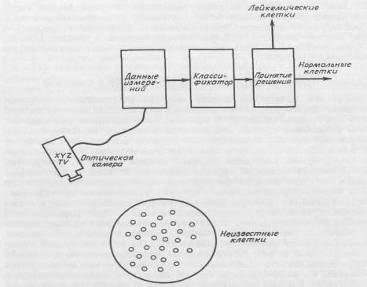
Рисунок 2.1.1 Схема оптической системы распознавания образов
Поскольку надежность такой классификации слишком низка, необходимо искать дополнительные признаки, которые могли бы оказаться полезными при различении разных типов клеток. Предположим, что лейкимические клетки имеют более ярко выраженную клеточную структуру, чем нормальные. В этом случае можно настроить камеру на измерение контрастности образцов и таким образом получить характеристику структурированности для каждой клетки эталонного набора образцов. В результате получим двумерную диаграмму, показанную на рис. 2.1.2
Цель методов отбора признаков — добиться наибольшего эффекта наименьшим числом признаков. Сокращение количества необходимых признаков облегчает процедуру классификации и в некоторых случаях увеличивает надежность результатов.
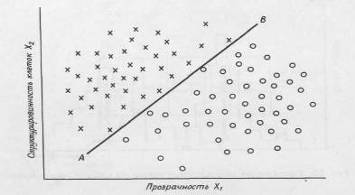
Рисунок 2.1.2 Разделение образов клеток на два класса в пространстве двух признаков — структурированности и прозрачности клеток.
Вся процедура распознавания образов складывается из трех последовательных операций: измерения, предварительной обработки и классификации. В результате применения этих операций последовательно формируются пространство измерений, пространство признаков и классификационное правило. Разделение всей процедуры распознавания образов на три стадии является несколько условным, поскольку приемы, используемые в одной из стадий, часто с успехом могут применяться и на других этапах обработки.
Предварительная обработка
С помощью методов предварительной обработки проводится преобразование исходных данных. К методам предварительной обработки относятся: масштабирование, нормализация, преобразования кластеризации, отбор признаков, многомерный скейлинг и нелинейное отображение.
Масштабирование и нормализация
Для преобразования данных, полученных разными датчиками, к виду, удобному для обработки, необходимо выбрать масштаб и выполнить нормализацию. Эти преобразования особенно важны, когда данные получены из разных источников. В этом случае они могут отличаться на несколько порядков величины, так что большие по величине дескрипторы будут подавлять малые. Этот недостаток может быть устранен путем автоматического выбора масштаба [17].
После преобразования масштаба желательно таким образом преобразовать данные, чтобы измерения, дающие больший вклад в кластеризацию, имели соответственно большие веса. Одним из простейших методов такого преобразования является метод дисперсионного взвешивания.
Хотя процедуры типа масштабирования могут уменьшить эффект разнородности исходных данных, а в методе дисперсионного взвешивания признаки получают веса, соответствующие их вкладу в кластеризацию, обе эти операции изменяют исходные данные одинаково.
Одним из недостатков методов предварительной обработки данных является то, что они учитывают все признаки, в том числе и те, которые могут не иметь отношения к рассматриваемой классификационной задаче. В результате возможно попадание в весьма неблагоприятную ситуацию, особенно в том случае, если несущественные признаки будут увеличивать ошибку процедуры классификации, не говоря уже о сложности и стоимости этих преобразований. Поскольку не все признаки существенны для решения рассматриваемой задачи, необходимо найти метод уменьшения их количества. Такой метод называется отбором признаков.
В результате выполнения этих преобразований мы переходим в новое пространство, в котором интересующий нас класс имеет минимальное внутриклассовое расстояние, а дисперсионная матрица выборки данных диагональная. Признаки, имеющие наименьшие значения дисперсии (диагональные элементы дисперсионной матрицы), считаются наиболее существенными для кластеризации. «Оптимальное» подмножество данных формируется из n признаков, имеющих наименьшие значения дисперсии.
Существуют еще несколько методов отбора наиболее информативных признаков. Такие критерии, как дивергенция помогают выделить наиболее существенные дескрипторы. Некоторые из этих методов основаны на гипотезе о виде распределения данных. Если такая гипотеза ошибочна, то результаты статистического анализа могут оказаться ненадежными. Еще одно затруднение заключается в том, что для выбора наилучшего набора дескрипторов должны быть проверены все возможные комбинации исходного набора дескрипторов. Такая проверка практически трудноосуществима в случае наборов признаков, объем которых n превышает 20, поскольку число вычислительных итераций возрастает как n!. Это приводит к дальнейшему снижению ценности рассматриваемых процедур. Требуются такие методы отбора признаков, которые, с одной стороны, были бы близки к оптимальным, а, с другой, не были бы сопряжены с большими объемами вычислений.