Математические методы проверки гипотезРефераты >> Статистика >> Математические методы проверки гипотез
План
ВВЕДЕНИЕ
1. ВАРИАЦИОННЫЙ РЯД. СТАТИСТИЧЕСКИЕ РАСПРЕДЕЛЕНИЯ ЭМПИРИЧЕСКАЯ ФУНКЦИЯ РАСПРЕДЕЛЕНИЯ
1. ВАРИАЦИОННЫЙ РЯД. СТАТИСТИЧЕСКИЕ РАСПРЕДЕЛЕНИЯ ЭМПИРИЧЕСКАЯ ФУНКЦИЯ РАСПРЕДЕЛЕНИЯ
2. ВЫБОРОЧНЫЕ ХАРАКТЕРИСТИКИ СТАТИСТИЧЕСКИХ РАСПРЕДЕЛЕНИЙ
3. ТОЧЕЧНЫЕ И ИНТЕРВАЛЬНЫЕ ОЦЕНКИ ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ
4. ПРОВЕРКА ГИПОТЕЗЫ О НОРМАЛЬНОМ РАСПРЕДЕЛЕНИИ ГЕНЕРАЛЬНОЙ СОВОКУПНОСТИ
ЗАКЛЮЧЕНИЕ
Список использованной литературы
ВВЕДЕНИЕ
Статистическая проверка гипотез является вторым после статистического оценивания параметров распределения и в то же время важнейшим разделом математической статистики. Методы математической статистики позволяют проверить предположения о законе распределения некоторой случайной величины (генеральной совокупности), о значениях параметров этого закона, о наличии корреляционной зависимости между случайными величинами, определенными на множестве объектов одной и той же генеральной совокупности. Пусть по некоторым данным имеются основания выдвинуть предположения о законе распределения или о параметре закона распределения случайной величины (или генеральной совокупности, на множестве объектов которой определена эта случайная величина). Задача заключается в том, чтобы подтвердить или опровергнуть это предположение, используя выборочные (экспериментальные) данные. Гипотезы о значениях параметров распределения или о сравнительной величине параметров двух распределений называются параметрическими гипотезами.
Гипотезы о виде распределения называются непараметрическими
гипотезами. Проверить статистическую гипотезу – это значит проверить, согласуются ли данные, полученные из выборки с этой гипотезой.
Проверка осуществляется с помощью статистического критерия. Статистический критерий – это случайная величина, закон распределения которой (вместе со значениями параметров) известен в
случае, если принятая гипотеза справедлива. Этот критерий называют еще критерием согласия(имеется в виду согласие принятой гипотезы с результатами, полученными из выборки).
Первый раздел посвящен основным понятиям математической статистики: вариационному ряду, статистическим распределениям.
Во втором разделе рассмотрены основные выборочные характеристики статистических распределение: математическому ожиданию. Выборочной дисперсии.
Третий раздел включает в себя изложение точечных и интервальных оценок распределений, теорию доверительных интервалов.
Четвертый раздел излагает основную и главную тему работы – теорию гипотез, являющуюся аналогом теории доверительных интервалов.
В заключении подведены итоги
1. ВАРИАЦИОННЫЙ РЯД. СТАТИСТИЧЕСКИЕ РАСПРЕДЕЛЕНИЯ. ЭМПИРИЧЕСКАЯ ФУНКЦИЯ РАСПРЕДЕЛЕНИЯ.
Полученная в результате статистического наблюдения выборка из n значений (вариант) изучаемого количественного признака X образует вариационный ряд. Ранжированный вариационный ряд получают, расположив варианты xj , где ![]() , в порядке возрастания значений, то есть
, в порядке возрастания значений, то есть ![]() .
.
Изучаемый признак X может быть дискретным, то есть его значения отличаются на конечную, заранее известную величину (год рождения, тарифный разряд, число людей), или непрерывным, то есть его значения отличаются на сколь угодно малую величину (время, вес, объем, стоимость).
Частотой mi в случае дискретного признака X называют число одинаковых вариант xi , содержащихся в выборке. В ранжированном вариационном ряду одинаковые варианты очевидно расположены подряд:
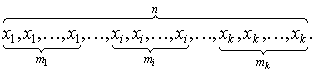
Вариационный ряд для дискретного признака X принято наглядно и компактно представлять в виде таблицы, в первой строке которой указаны k различных значений xi изучаемого признака, а во второй строке – соответствующие этим значениям частоты mi , где ![]() . Такую таблицу называют статистическим (выборочным) распределением.
. Такую таблицу называют статистическим (выборочным) распределением.
Переход от исходного вариационного ряда дискретного признака X к соответствующему статистическому распределению поясним на простом примере:
- вариационный ряд, полученный в результате статистического наблюдения (единицы измерения опускаем) – 7, 17, 14, 17, 10, 7, 7, 14, 7, 14;
- ранжированный вариационный ряд –
xj : ![]() , где
, где ![]() , n = 10;
, n = 10;
- соответствующее статистическое распределение (![]() , k = 4):
, k = 4):
|
xi |
7 |
10 |
14 |
17 |
|
mi |
4 |
1 |
3 |
2. |
Статистическое распределение для непрерывного признака X принято представлять интервальным рядом – таблицей, в первой строке которой указаны k интервалов значений изучаемого признака X вида (xi–1 – xi ), а во второй строке – соответствующие этим интервалам частоты mi , где ![]() . Обозначение (xi–1 – xi ) – указывает не разности, а все значения признака X от xi–1 до xi , кроме правой границы интервала xi .
. Обозначение (xi–1 – xi ) – указывает не разности, а все значения признака X от xi–1 до xi , кроме правой границы интервала xi .
Для непрерывного признака X частота mi – число различных xj , попавших в соответствующий интервал: xjÎ[xi–1 ; xi ):
|
|
|
| ||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
| ||||||||||||||||||||||||||||||||