Количественная оценка информации. ЛекцииРефераты >> Программирование и компьютеры >> Количественная оценка информации. Лекции
Построение образующего многочлена ![]() производится при помощи так называемых минимальных многочленов
производится при помощи так называемых минимальных многочленов ![]() , которые являются простыми неприводимыми многочленами (см. табл. 2, приложение 9). Образующий многочлен представляет собой произведение нечетных минимальных многочленов и являетсяих наименьшим общим кратным (НОК). Максимальный порядок
, которые являются простыми неприводимыми многочленами (см. табл. 2, приложение 9). Образующий многочлен представляет собой произведение нечетных минимальных многочленов и являетсяих наименьшим общим кратным (НОК). Максимальный порядок ![]() определяет номер последнего из выбираемых табличных минимальных многочленов
определяет номер последнего из выбираемых табличных минимальных многочленов
![]() (82)
(82)
Порядок многочлена используется при определении числа сомножителей ![]() . Например, если s = 6, то
. Например, если s = 6, то ![]() . Так как для построения
. Так как для построения ![]() используются только нечетные многочлены, то ими будут:
используются только нечетные многочлены, то ими будут: ![]() старший из них имеет порядок
старший из них имеет порядок ![]() . Как видим, число сомножителей
. Как видим, число сомножителей ![]() равно 6, т. е. числу исправляемых ошибок. Таким образом, число минимальных многочленов, участвующих в построении образующего многочлена,
равно 6, т. е. числу исправляемых ошибок. Таким образом, число минимальных многочленов, участвующих в построении образующего многочлена,
![]() (83)
(83)
а старшая степень
![]() (84)
(84)
(![]() указывает колонку в таблице минимальных многочленов,из которой обычно выбирается многочлен для построения
указывает колонку в таблице минимальных многочленов,из которой обычно выбирается многочлен для построения ![]() ).
).
Степень образующего многочлена, полученного в результате перемножения выбранных минимальных многочленов,
![]() (85)
(85)
В общем виде
![]() (86)
(86)
Декодирование кодов БЧХ производится по той же методике, что и декодирование циклических кодов с ![]() . Однако в связи с тем, что практически все коды БЧХ представлены комбинациями с
. Однако в связи с тем, что практически все коды БЧХ представлены комбинациями с ![]() , могут возникнуть весьма сложные варианты, когда для обнаружения и исправления ошибок необходимо производить большое число циклических сдвигов. В этом случае для облегчения можно комбинацию, полученную после
, могут возникнуть весьма сложные варианты, когда для обнаружения и исправления ошибок необходимо производить большое число циклических сдвигов. В этом случае для облегчения можно комбинацию, полученную после ![]() -кратного сдвига и суммирования с остатком, сдвигать не вправо, а влево на
-кратного сдвига и суммирования с остатком, сдвигать не вправо, а влево на ![]() циклических сдвигов. Это целесообразно делать только при
циклических сдвигов. Это целесообразно делать только при ![]() .
.
ТЕМА 8. СЖАТИЕ ИНФОРМАЦИИ
Сжатие информации представляет собой операцию, в результате которой данному коду или сообщению ставится в соответствие более короткий код или сообщение[19].
Сжатие информации имеет целью - ускорение и удешевление процессов механизированной обработки, хранения и поиска информации, экономия памяти ЭВМ. При сжатии следует стремиться к минимальной неоднозначности сжатых кодов при максимальной простоте алгоритма сжатия. Рассмотрим наиболее характерные методы сжатия информации.
Сжатие информации делением кода на части, меньшие некоторой наперед заданной величины А, заключается в том, что исходный код делится на части, меньшие А, после чего полученные части кода складываются между собой либо по правилам .двоичной арифметики, либо по модулю 2. Например, исходный код 101011010110; A = 4


Сжатие информации с побуквенным сдвигом в каждом разряде [5], как и предыдущий способ, не предусматривает восстановления сжимаемых кодов, а применяется лишь для сокращения адреса либо самого кода сжимаемого слова в памяти ЭВМ.
Предположим, исходное слово «газета» кодируетсякодом, в котором длина кодовой комбинации буквы l = 8:
Г - 01000111; а - 11110000; з - 01100011; е - 00010111; т - 11011000.
Полный код слова «Газета»
010001111111000001100011000101111101100011110000.
Сжатие осуществляется сложением по модулю 2 двоичных кодов букв сжимаемого слова с побуквенным сдвигом в каждом разряде.

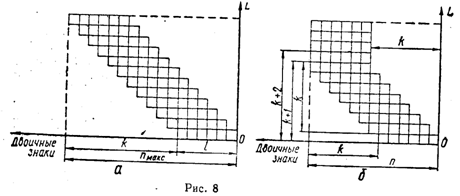
Допустимое количество разрядов сжатого кода является вполне определенной величиной, зависящей от способа кодирования и от емкости ЗУ. Количество адресов, а соответственно максимальное количество слов в выделенном участке памяти машины определяется из следующего соотношения
![]() (88)
(88)
где ![]() - максимально допустимая длина (количество двоичных разрядов) сжатого кода; N - возможное количество адресов в ЗУ. Если представить процесс побуквенного сдвига в общем виде, как показано на рис. 1, а, то длина сжатого кода
- максимально допустимая длина (количество двоичных разрядов) сжатого кода; N - возможное количество адресов в ЗУ. Если представить процесс побуквенного сдвига в общем виде, как показано на рис. 1, а, то длина сжатого кода
![]()
где k - число побуквенных сдвигов; ![]() - длина кодовой комбинации буквы.
- длина кодовой комбинации буквы.
Так как сдвигаются все буквы, кроме первой, то и число сдвигов ![]() , где L - число букв в слове. Тогда
, где L - число букв в слове. Тогда
![]()
В русском языке наиболее длинные слова имеют 23 - 25 букв. Если принять ![]() , с условием осуществления побуквенного сдвига с каждым шагом ровно на один разряд, для n и l могут быть получены следующие соотношения
, с условием осуществления побуквенного сдвига с каждым шагом ровно на один разряд, для n и l могут быть получены следующие соотношения
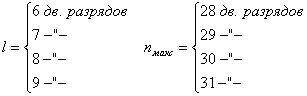
Если значение ![]() не удовлетворяет неравенству (88),можноконечные буквы слова складывать по модулю 2 без сдвига относительно предыдущей буквы, как это показано на рис 1, б.
не удовлетворяет неравенству (88),можноконечные буквы слова складывать по модулю 2 без сдвига относительно предыдущей буквы, как это показано на рис 1, б.
Например, если для предыдущего примера со словом “Газета” ![]() , сжатый код будет иметь вид:
, сжатый код будет иметь вид:

Метод сжатия информации на основе исключения повторения в старших разрядах последующих строк, массивов одинаковых элементов старших разрядов предыдущих строк массивов основан на том, что в сжатых массивах повторяющиеся элементы старших разрядов заменяются некоторым условным символом.
Очень часто обрабатываемая информация бывает представлена в виде набора однородных массивов, в которых элементы столбцов или строк массивов расположены в нарастающем порядке. Если считать старшими разряды, расположенные левее данного элемента, а младшими - расположенные правее, то можно заметить, что во многих случаях строки матриц отличаются друг от друга в младших разрядах. Если при записи каждого последующего элемента массива отбрасывать все повторяющиеся в предыдущем элементы, например в строке стоящие подряд элементы старших разрядов,то массивы могут быть сокращены от 2 до 10 и более разрядов [2].