Количественная оценка информации. ЛекцииРефераты >> Программирование и компьютеры >> Количественная оценка информации. Лекции
Для учета выброшенных разрядов вводится знак раздела ![]() , который позволяет отделить элементы в свернутом массиве. В случае полного повторения строк записывается соответствующе количество
, который позволяет отделить элементы в свернутом массиве. В случае полного повторения строк записывается соответствующе количество ![]() . При развертывании вместознака
. При развертывании вместознака ![]() восстанавливаются все пропущенные разряды, которые были до элемента, стоящего непосредственно за
восстанавливаются все пропущенные разряды, которые были до элемента, стоящего непосредственно за ![]() в сжатом тексте.
в сжатом тексте.
Для примера рассмотрим следующий массив:

Свернутый массив будет иметь вид:

Расшифровка (развертывание) происходит с конца массива. Переход на следующую строку происходит по двум условиям: либо по заполнению строки, либо при встрече ![]() .
.

Пропущенные цифры заполняются автоматически по аналогичным разрядам предыдущей строки. Заполнение производится с начала массива. Этот метод можно развить и для свертывания массивов, в которых повторяющиеся разряды встречаются не только с начала строки. Если в строке один повторяющийся участок, то кроме ![]() добавляется еще один дополнительный символ К, означающий конец строки. Расшифровка ведется от К до К. Длина строки известна. Нужно, чтобы оставшиеся между K цифры вместе с пропущенными разрядами составляли полную строку. При этом нам все равно, в каком месте строки выбрасываются повторяющиеся разряды, лишь бы в строке было не более одного участка с повторяющимися разрядами. Например:
добавляется еще один дополнительный символ К, означающий конец строки. Расшифровка ведется от К до К. Длина строки известна. Нужно, чтобы оставшиеся между K цифры вместе с пропущенными разрядами составляли полную строку. При этом нам все равно, в каком месте строки выбрасываются повторяющиеся разряды, лишь бы в строке было не более одного участка с повторяющимися разрядами. Например:
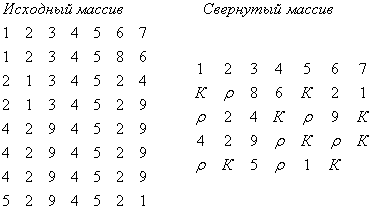
Если в строке есть два повторяющихся участка,то, используя этот метод, выбрасываем больший.
Процесс развертывания массива осуществляется следующим образом: переход на следующую строку происходит при встрече К

Пропущенные цифры заполняются по аналогичным разрядам предыдущей строки начиная с конца массива.
Если в строке массива несколько повторяющихся участков, томожно вместо ![]() вставлять специальные символы, указывающие на необходимое число пропусков.
вставлять специальные символы, указывающие на необходимое число пропусков.
Например, если обозначить количество пропусков, соответственно, Х - 2; Y - 3; Z - 5, то исходный и свернутый массивы будут иметь вид:

Процесс развертывания массива осуществляется следующим образом: длина строки известна, количество пропусков определяется символами X, Y, Z
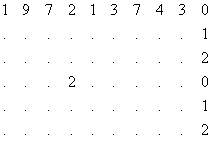
Пропущенные цифры заполняются по аналогичным разрядам предыдущей строки. Условием перехода на следующую строку является заполнение предыдущей строки.
Метод Г. В. Ливинского основан на том, что в памяти машины хранятся сжатые числа, разрядность которых меньше разрядности реальных чисел. Эффект сжатия достигается за счет того, что последовательности предварительно упорядоченных чисел разбиваются на ряд равных отрезков, внутри которых отсчет ведется не по их абсолютной величине, а от границы предыдущего отрезка. Разрядность чисел, получаемых таким образом, естественно, меньше разрядности соответствующих им реальных чисел [18, 21].
Для размещения в памяти ЭВМ М кодов, в которых наибольшее из кодируемых чисел равно N, необходим объем памяти
![]()
С ростом N длина кодовой комбинации будет расти как ![]() . Для экономии объема памяти Q, число
. Для экономии объема памяти Q, число ![]() , где выражение в скобках - округленное значение
, где выражение в скобках - округленное значение ![]() до ближайшего целого числа, разбивают на L равных частей. Максимальное число в полученном интервале чисел будет не больше
до ближайшего целого числа, разбивают на L равных частей. Максимальное число в полученном интервале чисел будет не больше ![]() . Величина
. Величина ![]() определяет разрядность хранимых чисел, объем памяти дляих хранения будет не больше
определяет разрядность хранимых чисел, объем памяти дляих хранения будет не больше ![]() . Если в памяти ЭВМ хранить адреса границ отрезков и порядковые номера хранимых чисел, отсчитываемых от очередной границы, то
. Если в памяти ЭВМ хранить адреса границ отрезков и порядковые номера хранимых чисел, отсчитываемых от очередной границы, то ![]() определяет разрядность чисел для выражения номера границы (в последнем интервале должно быть хотя бы одно число); объем памяти для хранения номеров границ будет
определяет разрядность чисел для выражения номера границы (в последнем интервале должно быть хотя бы одно число); объем памяти для хранения номеров границ будет ![]() где
где ![]() - число границ между отрезками (это число всегда на единицу меньше, чем число отрезков). Общий объем памяти приэтом будет не больше
- число границ между отрезками (это число всегда на единицу меньше, чем число отрезков). Общий объем памяти приэтом будет не больше
![]() (89)
(89)
Чтобы найти, при каких L выражение (89) принимает минимальное значение, достаточно продифференцировать его по Lи, приравнять производную к нулю. Нетрудно убедиться, что ![]() будет при
будет при
![]() [20] (90)
[20] (90)
Если подставить значение ![]() в выражение (89), то получим. значение объема памяти при оптимальном количестве зон, на, которые разбиваются хранимые в памяти ЭВМ числа,
в выражение (89), то получим. значение объема памяти при оптимальном количестве зон, на, которые разбиваются хранимые в памяти ЭВМ числа,
![]() (91)
(91)
Для значений ![]() при вычислениях можно пользоваться приближенной формулой
при вычислениях можно пользоваться приближенной формулой
![]() (92)
(92)
При поиске информации в памяти ЭВМ прежде всего определяют значение ![]() и находят величину интервала между двумя границами
и находят величину интервала между двумя границами
![]()
Затем определяют, в каком именно из интервалов находится искомое число х
![]()
После этого определяется адрес искомого числа как разность между абсолютным значением числа и числом, которое является граничным для данного интервала.
[1] Первичный алфавит составлен из m1 символов (качественных признаков), при помощи которых записано передаваемое сообщение. Вторичный алфавит состоит из m2 символов, при помощи которых сообщение трансформируется в код.
[2] Строго говоря, объема информации не существует. Мы вкладываем в этот термин то, что привыкли под этим подразумевать, - количество элементарных символов в принятом (вторичном) сообщении.