Протоколы ИнтернетРефераты >> Программирование и компьютеры >> Протоколы Интернет
1. Базовые сведения о X.500
Стандарт на службу каталогов X.500 был разработан изначально для организации публичных справочников общего доступа, позволяющий хранить информацию из любой области человеческих знаний. Он представляет собой набор рекомендаций комитета CCITT/ITU, описывающих исключительно принципы построения и форматы данных для взаимодействия систем, предоставляющих сервисы поиска в глобальных хранилищах информации. Выбор средств реализации полностью возлагается на разработчика. Существуют две редакции этих рекомендаций - 1988 и 1992 года.
Каталог (directory), построенный в соответствии с рекомендациями X.500, способен хранить информацию о наборе произвольного числа целевых объектов (objects of interest), имеющих различную структуру. Целевые объекты хранятся в информационной базе объектов (Directory Information Base или DIB). Каждый объект имеет связанный с ним набор сведений о структуре, свойствах и множестве разрешенных над ним действий, называемый классом объекта. Сами классы, в свою очередь, также трактуются как объекты.
Каждый экземпляр объекта, хранящийся в каталоге, обязан соответствовать одному из зарегистрированных в DIB классов. Для обеспечения непротиворечивости данных в каталоге, объекты должны создаваться и модифицироваться только в соответствии с правилами, предписанными классами этих объектов.
Для отражения того факта, что сущности реального мира могут содержать в себе вложенные сущности и одновременно содержаться внутри других сущностей, вводится иерархия сущностей. Сочетание информационной базы объектов и знаний об их иерархии образует дерево информационного каталога (Directory Information Tree или DIT). Как положено дереву (см. рисунок 5), оно имеет корень (root entry), узлы, называемые также контейнерами (container entry) и листья (leaf). Корень является стартовой точкой каталога. Объекты-контейнеры содержат в себе один или более объектов-листьев и/или других контейнеров. Листья не содержат вложенных объектов и, как правило, представляют собой собственно целевые объекты. Однако если объект создается "под" листом, лист становится контейнером.
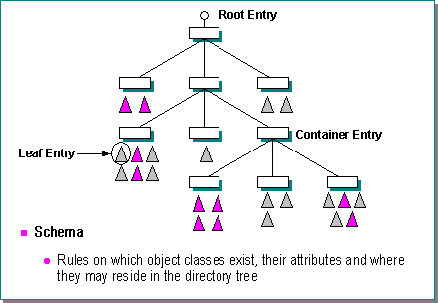
Рис. 5. Иерархия объектов каталога
Набор определений и правил, регулирующих структуру информационной базы, называют схемой каталога (Directory Schema). Схема каталога определяет, объекты каких классов могут быть созданы в рамках каталога, каков набор и каковы предельные значения их атрибутов, как они могут взаимодействовать друг с другом, и где в информационном дереве каталога могут находиться.
Внутри информационной базы каталога каждый объект должен иметь уникальное имя (name). Чтобы однозначно адресовать объект внутри информационной базы, его полное имя в базе также должно быть уникальным и отражать положение объекта в дереве каталога. Естественный способ получения такого имени - последовательное добавление к имени объекта имен уровней иерархии при движении вверх по дереву объектов. Рисунок 6 поясняет использование этого способа.
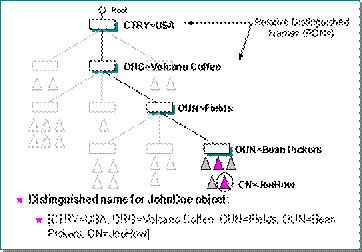
Рис. 6. Схема построения уникального имени
Полученное имя называют характерным именем (Distinguished Name или DN). Имена, получаемые на промежуточных уровнях, называют относительными характерными именами (Relative Distinguished Name или RDN). Эти имена могут использоваться при относительной адресации объектов каталога на каком-либо уровне иерархии. Строгого формата построения характерного имени именования спецификация X.500 не приводит.
Следует заметить, что, несмотря на некоторую схожесть формата адресов X.400 с форматом характерных имен, они имеют совершенно разную природу и свойства. Значения ключей в адресе X.400 может быть произвольным. В X.500, в связи с тем, что набор ключевых слов не определяется стандартом, напротив порядок следования ключей должен строго соответствовать пути к объекту в дереве каталога. В остальном адреса X.400 и X.500 вполне совместимы, и многие X.400-системы поддерживают настройки X.500 для ведения глобальных адресных книг и их автоматической репликации.
Для сокрытия внутренней структуры каталога и механизма работы с ним, в составе информационной системы должны присутствовать два компонента, уже ранее упоминавшихся: системный и пользовательский агенты каталога (DSA и DUA, соответственно). При обращении клиента к каталогу за информацией об интересующих его объектах, DUA выступает в роли промежуточного звена, преобразующего запрос в формат, понимаемый DSA, и возвращающий полученные результаты в ожидаемом пользователем виде. В свою очередь DSA принимает запросы со стороны пользовательских агентов и выполняет их или переадресует запрос другим системным агентам, если запрашиваемая информация не относится к обслуживаемой им части каталога. Каталог, представляемый единым информационным пространством, на практике может быть распределен между различными DSA. В составе информационной системы может быть произвольное количество системных агентов, каждый из которых отвечает за различные подмножества общего информационного дерева каталога. Та часть общего каталога, за обслуживание которой отвечает отдельный DSA, называется фрагментом (Fragment). Фрагмент может включать в себя произвольное количество поддеревьев из произвольных мест каталога.
Системный агент может использовать различную технику для обработки запросов, поступающих от пользовательского агента на те части каталога, которые не обслуживаются данным DSA:
цепной поиск (chaining), когда запрос при необходимости перенаправляется другому DSA, и результаты работы последнего возвращаются пользователю;
перенаправление (referral), когда системный агент инструктирует пользовательского агента, к какому DSA обратиться за нужной информацией.
Использование цепного поиска и перенаправления требует возможности непосредственного взаимодействия DSA, что не всегда выполнимо и накладывает существенные ограничения на область применения таких систем.
Чтобы сократить время, затрачиваемое на обработку пользовательского запроса, применяется метод репликации (replication) фрагментов между системными агентами каталога. В этом случае DSA отслеживает изменения, вносимые в подотчетный ему фрагмент, и доставляет их остальным системным агентам. В этом случае относительно актуальная копия всего каталога доступна для поиска каждому DSA системы, однако использование такой схемы требует дополнительных затрат ресурсов на размещение избыточных копий информации. Следует заметить, что для почтовых систем, данный вариант организации доступа к каталогу является единственно возможным, так как отдельные фрагменты могут не иметь непосредственного соединения друг с другом. Единицей репликации данных является пространство имен (Name Context), представляющее собой отдельную ветвь общего дерева. Рисунок 6 поясняет различия между фрагментом и пространством именования.