Нейрокомпьютерные системыРефераты >> Программирование и компьютеры >> Нейрокомпьютерные системы
Локальные минимумы
Обратное распространение использует разновидность градиентного спуска, т.е. осуществляет спуск вниз по поверхности ошибки, непрерывно подстраивая веса в направлении к минимуму. Поверхность ошибки сложной сети сильно изрезана и состоит из холмов, долин, складок и оврагов в пространстве высокой размерности. Сеть может попасть в локальный минимум (неглубокую долину), когда рядом имеется гораздо более глубокий минимум. В точке локального минимума все направления ведут вверх, и сеть неспособна из него выбраться. Статистические методы обучения могут помочь избежать этой ловушки, но они медленны. В [10] предложен метод, объединяющий статистические методы машины Коши с градиентным спуском обратного распространения и приводящий к системе, которая находит глобальный минимум, сохраняя высокую скорость обратного распространения. Это обсуждается в гл. 5.
Размер шага
Внимательный разбор доказательства сходимости в [7] показывает, что коррекции весов предполагаются бесконечно малыми. Ясно, что это неосуществимо на практике, так как ведет к бесконечному времени обучения. Размер шага должен браться конечным, и в этом вопросе приходится опираться только на опыт. Если размер шага очень мал, то сходимость слишком медленная, если же очень велик, то может возникнуть паралич или постоянная неустойчивость. В [II] описан адаптивный алгоритм выбора шага, автоматически корректирующий размер шага в процессе обучения.
Временная неустойчивость
Если сеть учится распознавать буквы, то нет смысла учить Б, если при этом забывается А. Процесс обучения должен быть таким, чтобы сеть обучалась на всем обучающем множестве без пропусков того, что уже выучено. В доказательстве сходимости [7] это условие выполнено, но требуется также, чтобы сети предъявлялись все векторы обучающего множества прежде, чем выполняется коррекция весов. Необходимые изменения весов должны вычисляться на всем множестве, а это требует дополнительной памяти; после ряда таких обучающих циклов веса сойдутся к минимальной ошибке. Этот метод может оказаться бесполезным, если сеть находится в постоянно меняющейся внешней среде, так что второй раз один и тот же вектор может уже не повториться. В этом случае процесс обучения может никогда не сойтись, бесцельно блуждая или сильно осциллируя. В этом смысле обратное распространение не похоже на биологические системы. Как будет указано в гл.8 это несоответствие (среди прочих) привело к системе ART , принадлежавшей Гроссбергу.
Глава 4 Сети встречного распространения
ВВЕДЕНИЕ В СЕТИ ВСТРЕЧНОГО РАСПРОСТРАНЕНИЯ
Возможности сети встречного распространения, разработанной в [5-7], превосходят возможности однослойных сетей. Время же обучения по сравнению с обратным распространением может уменьшаться в сто раз. Встречное распространение не столь общо, как обратное распространение, но оно может давать решение в тех приложениях, где долгая обучающая процедура невозможна. Будет показано, что помимо преодоления ограничений других сетей встречное распространение обладает собственными интересными и полезными свойствами. Во встречном распространении объединены два хорошо известных алгоритма: самоорганизующаяся карта Кохонена [8] и звезда Гроссберга [2-4] (см. приложение Б). Их объединение ведет к свойствам, которых нет ни у одного из них в отдельности. Методы, которые подобно встречному распространению, объединяют различные сетевые парадигмы как строительные блоки, могут привести к сетям, более близким к мозгу по архитектуре, чем любые другие однородные структуры. Похоже, что в мозгу именно каскадные соединения модулей различной специализации позволяют выполнять требуемые вычисления. Сеть встречного распространения функционирует подобно столу справок, способному к обобщению. В процессе обучения входные векторы ассоциируются с соответствующими выходными векторами. Эти векторы могут быть двоичными, состоящими из нулей и единиц, или непрерывными. Когда сеть обучена, приложение входного векторе приводит к требуемому выходному вектору. Обобщающая? способность сети позволяет получать правильный выxoд даже при приложении входного вектора, который являете; неполным или слегка неверным. Это позволяет использовать данную сеть для распознавания образов, восстановления образов и усиления сигналов.
СТРУКТУРА СЕТИ
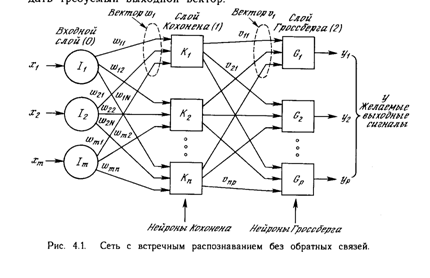
На рис. 4.1 показана упрощенная версия прямого действия сети встречного распространения. На нем иллюстрируются функциональные свойства этой парадигмы. Полная двунаправленная сеть основана на тех же принципах, она обсуждается в этой главе позднее. Нейроны слоя 0 (показанные кружками) служат лишь точками разветвления и не выполняют вычислений. Каждый нейрон слоя 0 соединен с каждым нейроном слоя 1 (называемого слоем Кохонена) отдельным весом wmn . Эти веса в целом рассматриваются как матрица весов W. Аналогично, каждый нейрон в слое Кохонена (слое 1) соединен с каждым нейроном в слое Гроссберга (слое 2) весом vnp . Эти веса образуют матрицу весов V. Все это весьма напоминает другие сети, встречавшиеся в предыдущих главах, различие, однако, состоит в операциях, выполняемых нейронами Кохонена и Гроссберга. Как и многие другие сети, встречное распространение функционирует в двух режимах: в нормальном режиме, при котором принимается входной вектор Х и выдается выходной вектор Y, и в режиме обучения, при котором подается входной вектор и веса корректируются, чтобы дать требуемый выходной вектор.
НОРМАЛЬНОЕ ФУНКЦИОНИРОВАНИЕ
Слои Кохоненна
В своей простейшей форме слой Кохонена функционирует в духе «победитель забирает все», т.е. для данного входного вектора один и только один нейрон Кохонена выдает на выходе логическую единицу, все остальные выдают ноль. Нейроны Кохонена можно воспринимать как набор электрических лампочек, так что для любого входного вектора загорается одна из них. Ассоциированное с каждым нейроном Кохонена множество весов соединяет его с каждым входом. Например, на рис.4.1 нейрон Кохонена К1 имеет веса w11, w21, .,wm1 составляющие весовой вектор W1. Они соединяются через входной слой с входными сигналами х1, х2 , .,хm, составляющими входной вектор X. Подобно нейронам большинства сетей выход NET каждого нейрона Кохонена является просто суммой взвешенных входов. Это может быть выражено следующим образом:
NETj = w1j x1+ w2j x2 + … + wm j xm (4.1)
где NETj - это выход NET-го нейрона Кохонена j ,
NETj = ![]() (4.2)
(4.2)
или в векторной записи N = XW (4.3)
где N - вектор выходов NET слоя Кохонена. Нейрон Кохонена с максимальным значением NET является «победителем». Его выход равен единице, у остальных он равен нулю.
Слой Гроссберга
Слой Гроссберга функционирует в сходной манере. Его выход NET является взвешенной суммой выходов k1 ,k2, ., kn слоя Кохонена, образующих вектор К. Вектор соединяющих весов, обозначенный через V, состоит из весов v11,v21 , ., vnp . Тогда выход NET каждого нейрона Гроссберга есть