Математическая теория обработки результатов экспериментовРефераты >> Технология >> Математическая теория обработки результатов экспериментов
εа = ![]() ;
;
Х = 14, 82 ± 0, 03 мм.
При a = 0,99:
Dх = ± 4,60×1,05×10-2 » 5×10-2 ( мм );
εа = ± ![]()
Х = 14, 82 ± 0,05 мм.
Результаты практически не отличаются, от результатов полученных из первой серии.
Найдем теперь погрешность результата всей серии из десяти измерений. В этом случае ![]() (мм);
(мм); ![]() (мм2).
(мм2).
Эти величины получаются суммированием последних строк из таблиц частных серий.
ао = 14, 80 мм;
а = ао + 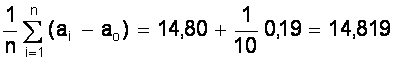 ( мм );
( мм );
а - ао = 0, 019 мм.
Sa2 = 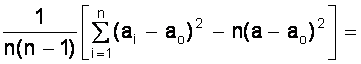
=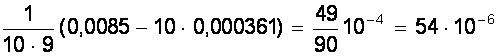 ( мм2 );
( мм2 );
Sa = 7, 35×10-3 мм.
При a = 0,95 имеем
Dх = ta×Sa = ± 2,26×7,35×10-3 = ± 1,7×10-2 ( мм );
εа = 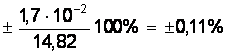 ;
;
а = 14, 819 ± 0, 017 мм.
При a = 0,99 получаем
Dх = ta×Sa = ± 3,25×7,35×10-2 = ± 2,4×10-2 ( мм );
εа = 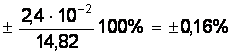 ;
;
а = 14, 819 ± 0, 024 мм.
Видно, что абсолютная и относительная погрешность результата десяти измерений стали почти в два раза меньше погрешностей пяти измерений.
Применение нормального распределения с s2 = S2n дает в случае a = 0,95 ka = 1,96 и Dх = 1,4 × 10-2 мм, а величина надежности понижается до 0,91; в случае a = 0,99 получаем ka = 2,58 и Dх = 1,9 × 10-2 мм, а величина надежности понижается до a = 0,97.
Как видно, с ростом числа измерений различие между результатами, вычислениями по распределению Стьюдента и по нормальному распределению уменьшается.
Контрольные вопросы
Цель математической обработки результатов эксперимента;
Виды измерений;
Типы ошибок измерения;
Свойства случайных ошибок;
Почему среднеарифметическое значение случайной величины при нормальном законе ее распределения является вероятнейшим значением?
Что такое истинная абсолютная и вероятнейшая ошибки отдельного измерения?
Что такое доверительный интервал случайной величины?
Что такое уровень значимости (надежности) серии измерений?
Геометрический смысл уровня значимости;
Почему при малом числе опытов нельзя погрешность измерений представить в виде Dх = ± Ksа?
Что является критерием “случайности” большого отклонения измеряемой величины?
Чем определяется величина случайной ошибки косвенных измерений?
Чем определяется точность числовой записи случайной величины?
ЗАКОНЫ РАСПРЕДЕЛЕНИЯ СЛУЧАЙНЫХ ВЕЛИЧИН
При характеристике случайных величин недостаточно указать их возможные значения. Необходимо еще знать насколько часто возникают различные значения этой величины. Это характеризуется вероятностью p отдельных ее значений.
Соотношение, устанавливающее связь между значениями случайной величины и вероятностями этих значений, называют законом распределения случайной величины. Различают интегральный и дифференциальный законы распределения.
Виды случайных величин и законы их распределения
Под случайной величиной понимается величина, принимающая в результате опыта какое либо числовое или качественное значение.
Случайная величина, принимающая конечное число или последовательность различных значений, называется дискретной случайной величиной. Случайная величина, принимающая все значения из некоторого интервала, называется непрерывной случайной величиной.
Под интегральным законом распределения (или функцией распределения) F (х) случайной величины Х понимают вероятность p того, что случайная величина Х не превысит некоторого ее значения х
F (х) = p (Х < х).
Основным свойством интегрального распределения является монотонное не убывание в ограниченном диапазоне [ 0; 1 ].
Действительно, если х1 и х2 некоторые значения случайной величины Х. Причем х2 > х1, то очевидно, что событие p (Х < х2) ³ p (Х < х1), т.к. между значениями х1 и х2 могут быть и промежуточные. Из определения интегрального закона следует, что F (х2) ³ F (х1), что говорит о монотонном не убывании функции. Очевидно также, что
F (- ¥) = p (Х < - ¥) = 0;
Þ F (¥) - F (- ¥) = 1,
F (+ ¥) = p (Х < ¥) = 1;
т.е. F (х) изменяется в диапазоне от 0 до 1.
Закон распределения дискретной случайной величины может быть задан таблицей или ступенчатой функцией (рис. 4)
Рис. 4. Интегральный закон распределения
дискретной случайной величины
Для дискретной случайной величины
F (x) = P (X < x) = P (-¥ < X < x) = 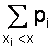 ,
,
![]() где суммирование распространяется на хi < х. В промежутке между двумя последовательными значениями Х функция F (х) постоянна. При переходе аргумента х через значение хi F (х) скачком возрастает на величину p (Х = хi).
где суммирование распространяется на хi < х. В промежутке между двумя последовательными значениями Х функция F (х) постоянна. При переходе аргумента х через значение хi F (х) скачком возрастает на величину p (Х = хi).
Рассмотрим p (х1 £ Х < х2). Если х2 > х1, то очевидно, что
p (Х < х2) = p (Х < х1) + p (х1 £ Х < х2).
Тогда
p (х1 £ Х < х2) = p (Х < х2) - p (Х < х1) = F (х2) - F (х1),
т.е. вероятность попадания случайной величины в интервал [х1; х2) равен разности значений интегральной функции граничных точек.
Последнее условие можно использовать для нахождения вероятности p (Х = х1) для непрерывной случайной величины. Для этого рассмотрим предел
p (X = x1) = ![]() ,
,
т.е. если закон распределения случайной величины есть функция непрерывная, то вероятность того, что случайная величина примет заранее заданное значение, равна нулю.
Здесь видно различие между дискретными и непрерывными случайными величинами. Для дискретных случайных величин, для каждого значения случайной величины существует своя вероятность. И для него справедливо утверждение: событие, вероятность которого равна нулю, невозможно. Для непрерывной случайной величины это утверждение неверно. Как показано, вероятность того, что Х = х1 ( где х1- заранее выбранное число) равна нулю, это событие не является невозможным.
Рассмотрим непрерывную случайную величину Х, интегральный закон которой предполагается непрерывным и дифференцируемым. Функцию
¦ (х) = F¢ (х)
называют дифференциальным законом распределения или плотностью вероятности случайной величины Х. Из определения производной можно записать
¦ (x) = F¢ (x) = 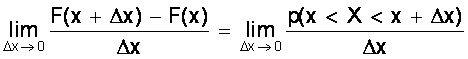 ,
,
т.е. плотность вероятности случайной величины Х в точке х равна пределу отношения вероятности попадания величины Х в интервал (х; х + Dх) к Dх, когда Dх стремится к нулю.