Логическая структуризация сетейРефераты >> Коммуникации и связь >> Логическая структуризация сетей
|
Байты кадра |
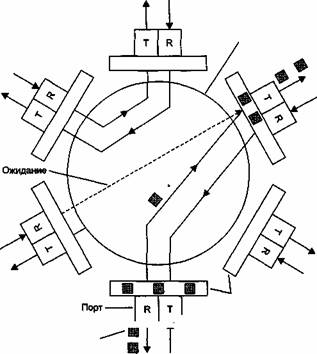
Рис. 4 Коммутационная матрица
Третья базовая архитектура взаимодействия портов — двухвходовая разделяемая память. Пример такой архитектуры приведен на рис. 5.
Входные блоки процессоров портов соединяются с переключаемым входом разделяемой памяти, а выходные блоки этих же процессоров соединяются с переключаемым выходом этой памяти. Переключением входа и выхода разделяемой памяти управляет менеджер очередей выходных портов. В разделяемой памяти менеджер организует несколько очередей данных, по одной для каждого выходного порта. Входные блоки процессоров передают менеджеру портов запросы на запись данных в очередь того порта, который соответствует адресу назначения пакета. Менеджер по очереди подключает вход памяти к одному из входных блоков процессоров и тот переписывает часть данных кадра в очередь определенного выходного порта. По мере заполнения очередей менеджер производит также поочередное подключение выхода разделяемой памяти к выходным блокам процессоров портов, и данные из очереди переписываются в выходной буфер процессора.
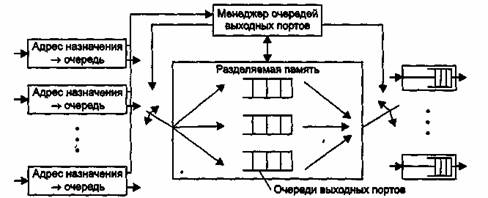
Рис. 5Архитектура разделяемой памяти
Память должна быть достаточно быстродействующей для поддержания скорости переписи данных между N портами коммутатора. Применение общей буферной памяти, гибко распределяемой менеджером между отдельными портами, снижает требования к размеру буферной памяти процессора порта.
У каждой из описанных архитектур есть преимущества и недостатки, поэтому в сложных коммутаторах эти схемы применяются в комбинации друг с другом.
Коммутатор(рис. 6) состоит из модулей с фиксированным количеством портов (2-12), выполненных на основе специализированной БИС, реализующей архитектуру коммутационной матрицы. Если порты, между которыми нужно передать кадр данных, принадлежат одному модулю, то передача кадра осуществляется процессорами модуля на основе имеющейся в модуле коммутационной матрицы. Если же порты принадлежат разным модулям, то процессоры общаются по общей шине. При такой архитектуре передача кадров внутри модуля будет происходить быстрее, чем при межмодульной передаче, так как коммутационная матрица — наиболее быстрый, хотя и наименее масштабируемый способ взаимодействия портов. Скорость внутренней шины коммутаторов достигает Гбайт/с, а у мощных моделей до десятков Гбайт/с. На рис. изображен подобный коммутатор
|
|
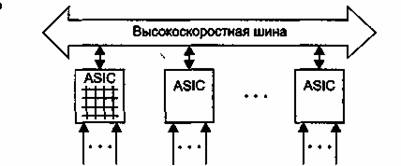
Рис. 6 Комбинированный коммутатор
1.2.2 Параметры коммутаторов
- скорость продвижений (forwarding)
- скорость фильтрации (filtering)
- пропускная способность коммутатора (throughput)
- время задержки передачи кадра
- тип коммутации
- размер адресной таблицы
- размер буферной памяти
Скорость продвижения, измеряемая в количестве кадров в секунду, определяет скорость, с которой происходит передача кадра между входным и выходным портами. Сам процесс передачи кадра включает в себя несколько этапов. Первый этап — это процесс буферизации либо всего кадра в целом, либо первых байтов кадра, содержащих адрес назначения. После определения адреса назначения кадра происходит процесс поиска искомого выходного порта в адресной таблице, которая может быть расположена либо в локальном кэше порта, либо в общей адресной таблице. После определения нужного выходного порта процессор принимает решение о продвижении кадра и посылает запрос на доступ к выходному порту. Установление необходимой связи между выходным и входным портами сопровождается передачей кадра в сеть через выходной порт.
Скорость фильтрации, так же как и скорость продвижения, измеряется в количестве кадров в секунду и характеризует скорость, с которой порт фильтрует, то есть отбрасывает ненужные для передачи кадры. Первый этап процесса фильтрации — это буферизация либо всего кадра, либо только первых адресных байтов кадра. После этого процессор просматривает адресную таблицу на предмет установления необходимого выходного порта. Определив, что адрес выходного порта совпадает с адресом входного порта, процессор принимает решение о фильтрации кадра и очищает свой буфер.
Скорость фильтрации и скорость продвижения зависят как от производительности процессоров портов, так и от режима работы коммутатора, о чем будет сказано далее. Наибольшего значения скоростей можно достигнуть при наименьшем размере кадров, так как в этом случае скорость их поступления максимальна. Как правило, скорость фильтрации является неблокирующей, то есть обработка кадров может происходить со скоростью их поступления.
Пропускная способность коммутатора, измеряемая в мегабитах в секунду (Мбит/с), определяет какое количество пользовательских данных можно передать через коммутатор за единицу времени. Максимальное значение пропускной способности достигается на кадрах максимальной длины, поскольку в этом случае доля накладных расходов на служебную информацию в каждом кадре мала.
Время задержки передачи кадра определяется как время, прошедшее с момента поступления первого байта кадра на входной порт коммутатора до момента появления этого байта на его выходном порте. Время задержки, так же как и скорость фильтрации и продвижения, зависит от типа коммутации, поэтому принято указывать лишь минимально возможное время задержки, которое составляет от единиц до десятков микросекунд.
Типы коммутации рассмотрены в пункте 1.2.
Размер адресной таблицы определяет то максимальное количество MAC-адресов, которое может хранить коммутатор. Обычно размер адресной таблицы приводится в расчете на один порт. Размер адресной таблицы зависит от области применения коммутаторов. Так, при использовании коммутатора в рабочей группе при микросегментации сети достаточно всего несколько десятков адресов. Коммутаторы отделов должны поддерживать несколько сот адресов, а коммутаторы магистралей сетей — до нескольких тысяч адресов. Размер адресной таблицы сказывается на производительности коммутатора только в том случае, если требуется больше адресов, чем может разместиться в таблице. Если адресная таблица порта коммутатора полностью заполнена и встречается кадр с адресом, которого нет в таблице, то процессор размещает этот адрес в таблице, вытесняя при этом какой-либо старый адрес. Эта операция отнимает у процессора порта часть времени, что снижает производительность коммутатора. Кроме того, если после этого порт получает кадр с адресом назначения, который пришлось предварительно удалить из таблицы, по процессор порта передает этот кадр на все остальные порты, так как не может определить адрес назначения. Это в значительной степени отнимает процессорное время у процессоров всех портов и создает излишний трафик в сети, что еще больше снижает производительность коммутатора.