Дисперсионный однофакторный анализРефераты >> Статистика >> Дисперсионный однофакторный анализ

Мы по-прежнему помним разницу между квадратом суммы исуммой квадратов!
Последовательность расчетов приведена в Табл. 7.
Таблица. 7 Последовательность операций в однофакторной модели дисперсионного анализа для связанных выборок
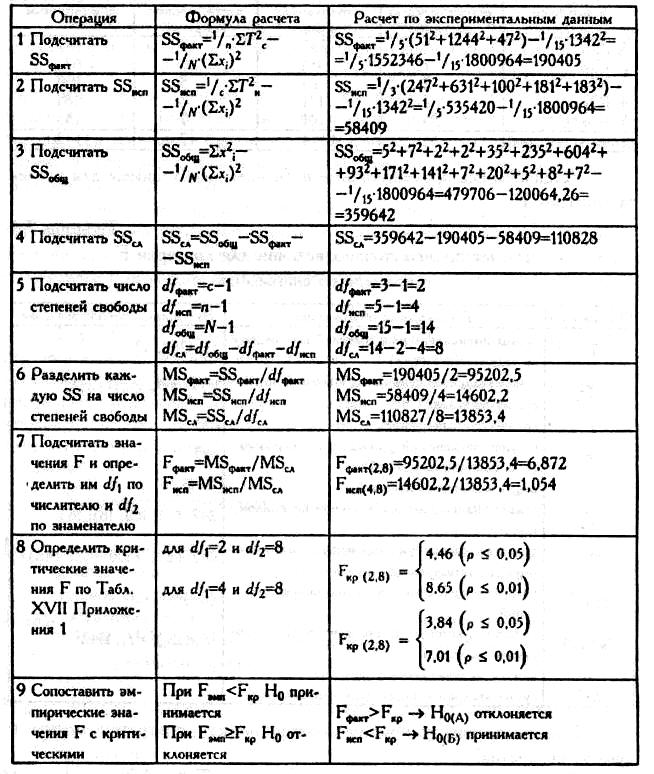
Вывод: H0(A) отклоняется. Различия в объеме воспроизведения слов в разных условиях являются более выраженными, чем различия, обусловленные случайными причинами (ρ<0,05).
H0(Б) принимается: Индивидуальные различия между испытуемыми являются не более выраженными, чем различия, обусловленные случайными причинами.
Однако, судя по Рис. 3, мы не можем утверждать, что срабатывает фактор длины анаграммы. Более значимыми оказываются качественные, а не количественные различия между анаграммами. Как мы уже имели возможность убедиться (см. параграфы 3.4 и 3.5), непараметрический L — критерий Пейджа подтверждает тенденцию увеличения индивидуальных показателей при переходе от анаграммы КРУА к анаграмме ИНААМШ, а затем к анаграмме АЛСТЬ (р<0,01). Значимые различия были получены и с помощью критерия Фридмана χ2r (ρ=0,0085).
Итак, непараметрические критерии позволяют нам констатировать более высокий уровень значимости различий между условиями!
Зачем же тогда использовать достаточно сложный дисперсионный анализ? Для того, чтобы подобрать существенные факторы, которые могут стать основой для формирования двух-, трех- и более факторных дисперсионных комплексов, позволяющих оценить не только влияние каждого из факторов в отдельности, но и их взаимодействие.
[1] Критерии F Фишера и метод углового преобразования Фишера, дающий нам критерий φ*, — это совершенно различные методы, имеющие разное предназначение и разные способы вычисления.
[2] Градаций может быть и две, но в этом случае мы не сможем установить нелинейных зависимостей и более разумным представляется использование более простых критериев (см. главы 2 и 3).
[3] Г.В. Суходольским (1972) предложена формула расчета дисперсионного отношения, которая позволяет получить более строгий результат:
![]()
где п - среднее количество наблюдений в каждой градации.
В данном случае Fэмп = 6,942 (ρ<0,01). Эта величина действительно ниже, чем в цитируемом примере. Однако для первого знакомства с дисперсионным анализом исследователям, обрабатывающим свои данные самостоятельно, в практических целях достаточно использовать приведенный алгоритм расчетов, используемый и в большинстве других руководств (Плохинский Н. А., 1960; Венецкий И. Г., Кильдишев Г.С., 1968; Ивантер Э.В., Коросов А.В.; 1992, Kurtz A.K., Mayo S.T, 1979 и др.).