Анализ работы многопроцессорных систем и обоснованность их применения в АСУРефераты >> Радиоэлектроника >> Анализ работы многопроцессорных систем и обоснованность их применения в АСУ
По виду взаимоотношений процессоров мультипроцессоры могут быть, кроме того, подразделены на системы с аутократическим управлением, с одной стороны, и системы с равноправными процессорами – с другой. В системах первого типа между процессорами имеют место отношения ''хозяев'' и ''подчиненных''. В системах с равноправными процессорами все они имеют одинаковые возможности доступа к общей шине.
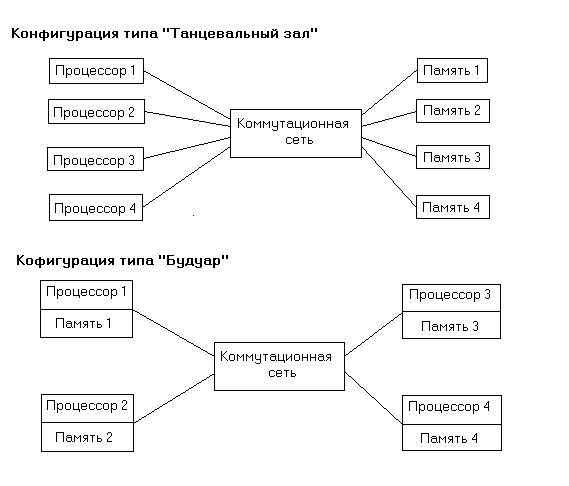 |
Для описания способа организации параллельных вычислений используется также понятие одновременность, котороеозначаетнезависимое, асинхронное функционирование параллельно работающих вычислительных устройств в противоположность их синхронному (или жесткому) взаимодействию в составе мультипроцессорной системы.
Перспективные многопроцессорные системы.
Систолические и волновые матрицы.
Для цифровой обработки сигналов используются матричные вычислительные структуры двух следующих видов.
Систолический процессор, представляющий собой регулярную матрицу процессорных элементов, каждый из которых обменивается информацией со своими ближайшими соседями, причем все процессоры работают синхронно под управлением общего источника синхронизации, частота которой ограничивается быстродействием самого медленного процессора матрицы. Происхождением термина систолический является аналогия между ритмическими сокращениями сердечной мышцы и синхронной прокачкой данных через матрицу процессорных элементов.
Волновой процессор, также представляющий собой матрицу процессорных элементов, которые обмениваются информацией с ближайшими соседями, но функционирует в условиях отсутствия единого источника синхронизации. В таком процессоре имеют место одновременность работы элементов и управление данными. Управление каждым процессорным элементом осуществляется локально, причем выполнение операции инициируется поступлением входных данных после того, как результат предыдущей операции выведен в соответствующий соседний процессор. ''Волны'' обработки распространяются по матрице по мере того, как процессорные элементы передают выходные данные своим соседям.
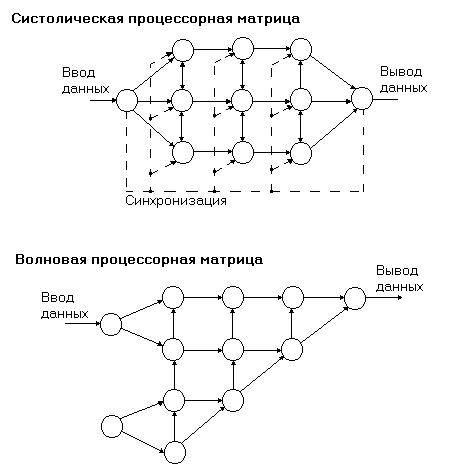 |
Рис. иллюстрирует различие между систолическими и волновыми матрицами процессорных элементов. Для реализации и систолических, и волновых мультипроцессоров, в которых каждый элемент представляет собой 32-разрядный микропроцессор, могут быть применены транспьютеры Т414. Возможен и другой подход, при котором матрица строится из одноразрядных микропроцессоров, причем множество таких элементарных процессоров размещается конструктивно в одной интегральной схеме.
Геометрически-арифметический параллельный процессор (GAPP) фирмы NCR представляет собой двумерную однокристальную матрицу, содержащую 72 одноразрядных процессора, каждый из которых имеет ЗУПВ емкостью 128 бит. Из нескольких GAPP могут быть построены матрицы большой размерности, предназначенные для обработки изображений и сигналов, а также для работы с базами данных. Обработка слов данных с помощью GAPP осуществляется параллельно, причем действия над словами переменной длины выполняются путем последовательной обработки их разрядов (параллельная обработка слов – последовательная обработка битов). GAPP представляет собой скорее матричный процессор класса ОМКД, нежели систолическую матрицу, так как в нем имеется возможность подачи данных на все ячейки. Однако эта способность GAPP реализуется с помощью протяженных межсоединений, которые снижают скорость. В то же время GAPP может служить основой для построения систолических матриц.
Процессоры CLIP фирмы Stonefield (разработанный в Лондонском университетском колледже в 70-х годах) и DAP фирмы ICL являются матричными процессорами, представляющими собой БИС, содержащие одноразрядные процессорные элементы. CLIP применяется главным образом для обработки изображений, а ICL DAP в основном используется для реализации алгоритмов быстрой обработки сигналов и числовых расчетов.
Интегральный систолический матричный процессор был разработан в исследовательском центре GEC Hirst. МА717 представляет собой систолическую матрицу, в которую данные вводятся через периферийные элементы, а движение их по матрице происходит в виде протоков от элемента к элементу. Рабочая частота устройств, реализуемых на принципах этой систолической архитектуры, может почти в два раза превышать рабочую частоту процессоров GAPP.
Матричные процессоры.
Для реализации обработки сигналов матрицы МКМД могут быть организованы в виде систолических или волновых матриц. Систолическая матрица состоит из отдельных процессорных узлов, каждый из которых соединен с соседними посредством упорядоченной решетки. Большая часть процессорных элементов располагает одинаковыми наборами базовых операций, и задача обработки сигнала распределяется в матричном пространстве по конвейерному принципу. Процессоры работают синхронно, используя общий задающий генератор тактовых сигналов, поступающих на все элементы.
В волновой матрице происходит распределение функции между процессорными элементами, как в систолической матрице, но в данном случае не имеет места общая синхронизация от задающего генератора. Управление каждым процессором организуется локально в соответствии с поступлением необходимых входных данных от соответствующих соседних процессоров. Результирующая обрабатывающая волна распространяется по матрице по мере того, как обрабатываются входные данные, и затем результаты этой обработки передаются другим процессорам в матрице.
Вычислительная поверхность Meiko.
Вычислительная поверхность Meiko была разработана инженерами и программистами, работавшими над проектированием транспьютера Inmos; они поставили перед собой задачу построить на основе транспьютеров гибкую, наращиваемую мини-суперЭВМ, характеризующуюся отношением стоимость/производительность около 250 долл./(млн. операций/с) и максимальной производительностью свыше 1000 млн. операций/с.