Интерпретация блок-схемРефераты >> Программирование и компьютеры >> Интерпретация блок-схем
На втором этапе трансляции выполняется синтаксический анализ, в задачу которого входит распознавание типа предложений и выявление структуры программы, а также синтаксический контроль, выявляющий синтаксические ошибки.
На третьем этапе производиться семантический анализ, в ходе которого проводится исследование каждого предложения и генерирование семантически эквивалентных предложений объектного языка. Иными словами, на третьем этапе выполняется собственно перевод.
Иногда вводят еще один этап, на котором производится оптимизация программы с целью сокращения времени ее выполнения и минимизации используемой программой памяти.
В трансляторах каждому из описанных этапов соответствует определенная часть транслятора. Иногда отдельные блоки выполняют одновременно несколько этапов, например семантический анализ, оптимизацию и генерирование предложений входного языка. Также существуют трансляторы, в которых описанная общая схема повторяется несколько раз, например, при переводе с выходного языка на внутренний, с внутреннего на промежуточный, выходной или объектный.
Транслятор, предложенный в данной работе, имеет следующую структуру:
 | |||||
 | |||||
 | |||||
Оптимизация не выполняется.
4.3.2. Лексический анализ
4.3.2.1. Задачи лексического анализа
Цель лексического анализа состоит в переводе исходной программы на стандартный, входной язык компилятора и преобразовании ее к виду, удобному для дальнейшей обработки на этапах синтаксического и семантического анализа.
В процессе лексического анализа обычно собираются из отдельных знаков (букв и цифр) простые синтаксические конструкции: идентификаторы, числа, а также служебные слова типа begin, end и другие. При дальнейшей обработке такие простые конструкции рассматриваются как неделимые, поэтому оставлять их распознавание и сборку до этапа синтаксического анализа невыгодно, прежде всего, с точки зрения общего времени и сложности алгоритмов трансляции.
В общем случае в процессе лексического анализа необходимо выполнить следующее:
1) перекодировать исходную программу, рассматриваемую как входная строка, и привести ее к стандартному входному языку;
2) выделить и собрать из отдельных знаков в слова идентификаторы и служебные слова (основные символы языка);
3) выделить и собрать из цифр, а также перевести в машинную форму числовые константы.
В некоторых компиляторах лексический анализ составляет отдельный этап и выполняется специальными блоками за один – два просмотра входной программы. В других компиляторах отдельные задачи лексического анализа решаются на разных этапах трансляции. Однако перекодирование входной программы и приведение ее к стандартному входному языку всегда выполняет первый блок компилятора.
В ходе лексического анализа помимо чисто лексического контроля (выявление недопустимых символов и служебных слов, а также ошибок записи идентификаторов и констант) иногда выполняют частичный синтаксический контроль. В частности, при лексическом анализе легко проверяется парность некоторых основных символов.
Другой вид контроля, иногда применяемый при лексическом анализе, - проверка сочетаемости стоящих рядом символов. Например, пары символов begin x и else begin – сочетаемы (допустимы), но те же символы, стоящие в обратном порядке: x begin и begin else – несочетаемы. В то же время пары +end, +/, *[ - несочетаемы ни в каком порядке. Основной (главной) частью лексического анализатора является сканер.
4.3.2.2. Сканер
Сканер – это часть компилятора, которая читает входную программу и формирует лексемы: константы, знаки операций и т.д. Он также выполняет лексический контроль. Синтаксис лексем прост, его можно задать автоматными грамматиками, так как его можно легко запрограммировать. Следовательно, сканер выделяют отдельным блоком.
Синтаксис каждой лексемы можно задать с помощью диаграммы состояний. Следовательно, алгоритм работы сканера можно задать с помощью правила анализа по диаграмме состояний. Заметим, что процедура анализа представляет собой восходящий анализ, основой на каждом шаге является текущий символ и текущее состояние. Поэтому диаграмма состояний представляет собой граф, подграфы которого это есть диаграммы состояний отдельных лексем.
Сканер программируется так, что на каждом шаге он выделяет одну лексему.
Пусть входная строка: s1, s2, s3,…, sn.
![]()
![]()
![]() s,i СКАНЕР L,t
s,i СКАНЕР L,t
где L – лексема, t – ее тип.
0, константа типа int
1, константа типа long_int
t= 2, константа типа float
3, константа типа char
4, идентификатор
-1, ошибка, не распознаваемый тип лексемы
Сканер в процессе своей работы распознает тип символа, то есть использует подпрограмму:
![]()
![]() si класс символа k
si класс символа k
![]() где
где
1, если si буква
2, если si цифра
3, если si `
k= 4, если si “ или ”
5, если si верный знак
0, если si ошибочный символ
Тогда диаграмма состояний имеет вид: (смотри в приложении).
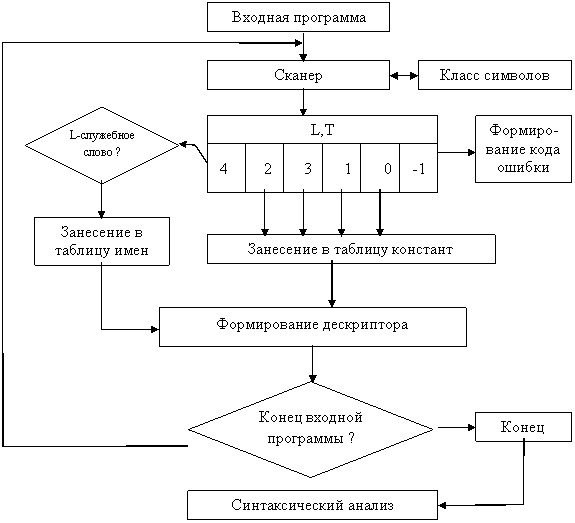 |
Рис.3. Блок схема лексического анализа.
ЗАМЕЧАНИЕ:
1. В каждом состоянии сканер может выполнять дополнительные действия по контролю правильности лексемы и преобразования во внутреннюю форму.
2. Сканер выделяет самую длинную лексему пока возможно, а при выходе указатель стоит на начале следующей лексемы.