Интерпретация блок-схемРефераты >> Программирование и компьютеры >> Интерпретация блок-схем
Изобразим блок - схему работы лексического анализатора (рис.3.).
Так как сканер строится по диаграмме состояний, то для простоты программирования был построен конечный автомат. Матрица переходов состояний сканера приведена в приложении.
4.3.3. Синтаксический и семантический анализ
Анализаторы выполняют действительно сложную работу по расчленению исходной программы на составные части, формированию ее внутреннего представления и занесению информации в таблицу символов и другие таблицы. При этом также выполняется полный синтаксический и частичный семантический контроль программы.
Обычный анализатор представляет собой синтаксически управляемую программу. В действительности стремятся отделить синтаксис от семантики настолько, насколько это возможно. Когда синтаксический анализатор (распознаватель) узнает конструкцию исходного языка, он вызывает соответствующую семантическую процедуру, или семантическую программу, которая контролирует данную конструкцию с точки зрения семантики и затем запоминает информацию о ней в таблице символов или во внутреннем представлении программы. Например, когда распознается описание переменных, семантическая программа проверяет идентификаторы, указанные в этом описании, чтобы убедиться в том, что они не были описаны дважды, и заносит их вместе с атрибутами в таблицу символов.
Когда встречается инструкция присваивания вида:
<переменная> = <выражение>
семантическая программа проверяет переменную и выражение на соответствие типов и затем заносит инструкцию присваивания в программу во внутреннее представление.
Синтаксический анализ можно представить диаграммой состояний, так же как и сканер. Поэтому их частично объединяют и если возможно то совмещают полностью. В данной работе процесс лексического, синтаксического и семантического анализа для всех блоков разделен. Матрицы состояний конечных автоматов синтаксического анализа блоков приведены в приложении. Семантический анализ выполняется в процессе интерпретации.
4.3.4. Польская инверсная запись (ПолИЗ)
Первые процедурно-ориентированные языки программирования высокого уровня предназначались для решения инженерных и научно – технических задач, в которых широко применяются методы вычислительной математики. Значительную часть программ решения таких задач составляют арифметические и логические выражения. Поэтому трансляцией выражений занимались очень многие исследователи и разработчики трансляторов. На данное время разработано большое число таких трансляторов. Сейчас классическим стал метод трансляции выражений, основанный на использовании промежуточной обратной польской записи, названной так в честь польского математика Яна Лукашевича, который впервые использовал эту форму представления выражений в математической логике.
Цель польской инверсной записи – представить операции исходного выражения в порядке их выполнения (вычисления). В данной работе был использован алгоритм построения ПолИЗа, который был предложен Дейкстрой.
Пример ПолИЗа:
Исходное выражение : x=a+f*c;
Выражение на ПолИЗе :xafc*+=.
Очевидно, что обрабатывать такую последовательность операций значительно легче, так как они расположены в порядке их выполнения. Рассмотрим алгоритм Дейкстры для формирования ПолИЗа.
4.3.4.1. Алгоритм Дейкстры формирования ПолИЗа
ПРИОРИТЕТ ОПЕРАЦИИ – это целое число, означающее старшинство операции по отношению к другим операциям. Приоритет операций изменяется с использованием скобок ( и ).
Исходная последовательность просматривается слева на право, как входная последовательность элементов.
АЛГОРИТМ:
1. Если элемент операнд, то он заносится в ПолИЗ.
2. Если элемент операция, то она заносится в ПолИЗ через СТЕК по правилу.
2.1. Если СТЕК пуст, то знак операции заносится в СТЕК,
2.2. Иначе: если приоритет входного знака равен 0, то он заносится в СТЕК, иначе сравниваются приоритеты входного знака и знака в вершине СТЕКа.
2.3.Если приоритет входного знака больше приоритета знака в вершине СТЕКа, то он заносится в СТЕК.
2.4. Иначе из СТЕКа выталкиваются все знаки с приоритетом больше или равным приоритету входного знака в вершине СТЕКа и приписываются к ПолИЗу, затем входной знак заносится в СТЕК.
3. Особо обрабатываются ( и ).
( - имея приоритет 0 сразу же заносится в СТЕК по 2.2.
) – имея приоритет равный 1 выталкивает из СТЕКа все знаки до ближайшей открывающей скобки (, затем они взаимно уничтожаются.
4. При появлении признака конца выражения ( в нашем случае ;) СТЕК очищается : все оставшиеся знаки выталкиваются и приписываются к ПолИЗу.
Так же ПолИЗу соответствует так называемое дерево ПолИЗа.
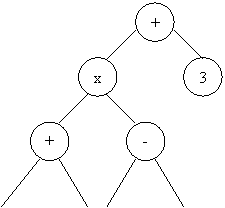
Пример: (x+a)*(x-b)+3;
Дерево:
 |
x a x b
ПолИЗ: x a + x b - * 3 +.
Построение ПолИЗа по дереву осуществляется обходом дерева по правилу левое поддерево, правое поддерево, корень.
4.3.4.2. ПолИЗ выражений, содержащих переменные синтаксиса
Кроме операций сложения и умножения любая программа содержит операции вычисляющие адреса элементов массива в зависимости от индексных выражений. Например:
a[i+1]-b[i,j-1]*a[2*i+1]
Индексные выражения.
Выведем формулы вычисления адресов элементов массива.
Для одномерного массива а, описание которого на Паскале и Си имеет вид:
a: array [1 n] of integer; // Pascal
int a[n]; // C/C++
и каждый элемент имеет массива занимает k-байт.
Адрес первого элемента равен A . Выясним чему будут равны адреса других элементов. Для этого рассмотрим расположение элементов массива в физической памяти ЭВМ.
![]()
![]()
![]()
![]()
![]()
![]() A +k +2k +3k A+k*(i-1)…
A +k +2k +3k A+k*(i-1)…
k байт
![]()