Принципы реализации машин БДРефераты >> Программирование и компьютеры >> Принципы реализации машин БД
/\ - универсальный обрабатывающий / / -коммуникационный процессор процессор (серийный микропроцессор)
- специализированный - коммутирующее устройство (общая обрабатывающий процессор шина, переключательная матрица, О - локальная полупроводниковая память кольцевая коммутирующая шина, коммутирующая сеть)
- буферная общедоступная память - Управляющий процессор (подсистема)
- устройство массовой памяти с контроллером (НМД с контроллером)
Рис. 2. Топология коммерческих МБД
структурная обработка или обработка метаданных, заключающаяся в поддержке вспомогательных структур данных (индексация, мультиатрибутная кластеризация) . 2. Наличие системной буферной памяти (СБП) между первыми двумя уровнями обработки, в которой помещаются отношения или вспомогательные структуры данных, полученные на первом уровне обработки. Такая архитектура предполагает наличие опережающей выборки и подкачки данных из уровня первичной обработки (стадирование). СБП при этом обязательно должна быть двух или более портовой. 3. Наличие функционального параллелизма, при котором различные функции первичной и вторичной обработки реализуются на физически распределенной аппаратуре. При этом часть функциональных устройств реализуется на универсальных микропроцессорах, часть в виде спецаппаратуры (например, заказных СБИС). Функциональный параллелизм позволяет реализовать конвейерное выполнение транзакций и отдельных запросов. В более общих случаях для увеличения производительности допускается дублирование функциональных процессоров на наиболее трудоемких операциях. В качестве наиболее типичных примеров таких МН МВД можно рассмотреть DELTA и GRACE. Японский проект МВД (рис. 3) лежит в основе вычислительной системы 5-го поколения. Действующий в настоящее время прототип состоит из двух подсистем:
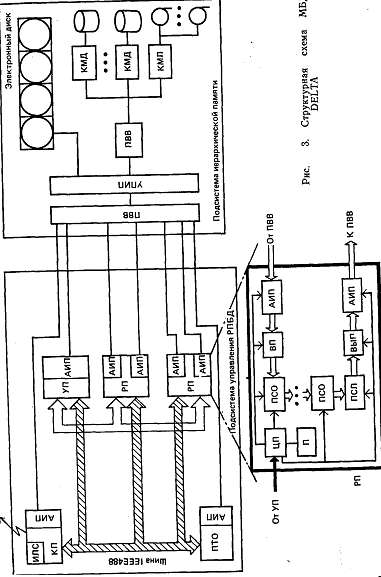 подсистемы вторичной обработки в составе четырех реляционных процессоров (РП), одного процессора управления (УП), одного коммуникационного процессора (КП) и одного процессора технического обслуживания (НТО), выполняющего функции диагностики системы, поддержки БД, связи с операторам и т. п.;
подсистемы вторичной обработки в составе четырех реляционных процессоров (РП), одного процессора управления (УП), одного коммуникационного процессора (КП) и одного процессора технического обслуживания (НТО), выполняющего функции диагностики системы, поддержки БД, связи с операторам и т. п.;
подсистемы иерархической памяти (ИЛ), содержащей системную буферную память (электронный кэш-диск емкостью 128 Мбайт), массовую память с восемью НМД (с контроллером магнитного диска КМД) общей емкостью 20 Гбайт и четырьмя НМЛ (с контроллером магнитной ленты - КМЛ) , а также универсальную микроэвм в качестве управляющего процессора иерархической памяти (УПИП) и процессора ввода-вывода (ПЕВ). Связь между подсистемами осуществляется высокоскоростным каналом со стандартным интерфейсом со скоростью передачи до 3 Мбайт/с. Все процессоры подсистемы вторичной обработки подключаются к этому каналу посредством ПВВ через специальные адаптеры иерархической памяти (АИП).
Основным функциональным узлом МЕД DELTA является реляционный процессор (РП) баз данных, назначение которого-выполнение операций реляционной алгебры над отношениями произвольного объема с высокой производительностью. Каждый из четырех РП может выполнять отдельную операции:
процессора (КП) и одного процессора технического обслуживания (НТО), выполняющего функции диагностики системы, поддержки БД, связи с оператором и т. п.;
подсистемы иерархической памяти (ИЛ), содержащей системную буферную память (электронный кэш-диск емкостью 128 Мбайт), массовую память с восемью НМД (с контроллером магнитного диска КМД) общей емкостью 20 Гбайт и четырьмя НМЛ (с контроллером магнитной ленты - КМЛ) , а так же универсальную микроэвм в качестве управляющего процессора иерархической памяти (УДИЛ) и процессора ввода-вывода (НЕЕ). Связь между подсистемами осуществляется высокоскоростным каналом со стандартным интерфейсом со скоростью передачи до 3 Мбайт/с. Все процессоры подсистемы вторичной обработки подключаются к этому каналу посредством ПВВ через специальные адаптеры иерархической памяти (АИП).
Основным функциональным узлом МЕД DELTA является реляционный процессор (РП) баз данных, назначение которого-выполнение операций реляционной алгебры над отношениями произвольного объема с высокой производительностью. Каждый из четырех РП может выполнять отдельную операцию реляционной алгебры независимо от других или все они могут выполнять одну операцию параллельно (например, сортировку отношений в ИЛ). РП имеет регулярную структуру (см. рис. 3) для облегчения его реализации в виде СБИС. Кроме этого он в своем составе имеет центральный процессор (ЦП) с памятью 512 Кбайт для реализации операций с обширной логикой (например, агрегатных функций типа min, mах и т. п.). Для облегчения входного (ВП) и выходного (ВЫП) потока данных РП содержит два адаптера иерархической памяти (АИП), а также входной модуль для подготовки кортежей отношений (например, перестановки значений атрибутов). Собственно операция реляционной алгебры реализуется в РП. Процессор слияния (ПСЛ) сортированных сегментов отношений предназначен для слияния сортированных сегментов отношений, а также в нем реализуются операции естественного соединения двух отношений и селекции отношения. Двенадцать процессоров сортировки (ПСО) предназначены для реализации конвейерной однопроходовой сортировки сегмента отношения объемом 64 Кбайт. ПСО и ПСЛ реализованы полностью аппаратно.
Иерархическая память в DELTA является наиболее сложной подсистемой, в функции которой входят:
управление СЕЛ и УМП;
стадирование данных (в виде сегментов отношений) из УМП в СБП в соответствии с заявками РП;
селекция и вертикальная фильтрация отношений при помещении их в СБП с привлечением специального (атрибутного) метода хранения отношений в УМП;
поддержка индексных структур, кластеризация отношений в УМП и организация с их помощью быстрого поиска в УМП.
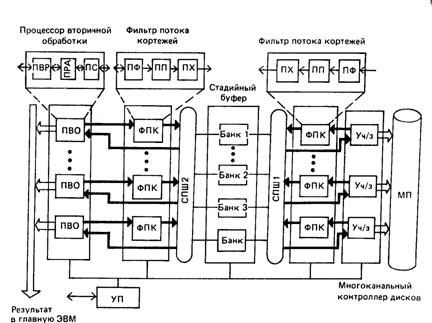
Рис. 4. Структурная схема МВД GRACE
Вторым примером МН МВД является также японский проект GRACE, структурная схема которого приведена на рис. 4. СБП реализована здесь набором электронных дисков на цилиндрических магнитных доменах. В качестве УМП использованы многоканальные НМД, в каждый канал которых встроены, кроме устройств чтения-записи (Уч/з), процессоры первичной обработки, названные фильтрами потока кортежей (ФПК). Каждый ФПК содержит:
процессор фильтрации (ПФ), осуществляющий в пределах дорожки МД собственно псевдоассоциативный поиск кортежей, удовлетворяющих заданному условию;
процессор проекции (ПП) и преобразования кортежей; процессор хэширования (ПХ), реализующий динамическую сегментацию кортежей читаемого отношения.
Фильтр потока кортежей работает в конвейерном режиме и позволяет обрабатывать поступающие из УМП кортежи со скоростью их чтения (обработка «в полете»).
На уровне вторичной обработки применяются процессоры вторичной обработки (ПВО) и ФПК. Назначение ФПК - выполнять описанную выше обработку кортежей результирующих отношений, поступающих из ПВО в СЕЛ. ПВО содержит наряду с процессором реляционной алгебры (ПРА), реализованным на основе универсального микропроцессора со своей локальной памятью, также аппаратный процессор сортировки отношений (ПСО) и процессор выдачи результата (ПВР) в канал главной ЭВМ. ПСО осуществляет потоковую сортировку сегмента отношения, поступающего из банка СЕЛ в процессор реляционной алгебры. Двухпортовые банки СЕЛ подсоединяются к процессорам обработки обоих уровней посредством специальных петлевых шин (СПШ). Эти многоканальные шины с разделением времени осуществляют на каждом уровне обработки коммутацию любого процессора обработки к любому банку памяти и одновременную обработку нескольких банков памяти.