Принципы реализации машин БДРефераты >> Программирование и компьютеры >> Принципы реализации машин БД
на выходную шину, если сравнение было успешным;
в линию обратной связи (ЛОС), если, например, из входного модуля по шине управления пришла команда о том, что в следующем кортеже второго отношения то же значение атрибута соединения (для операции соединения) и этот выводимый кортеж надо повторно с ним сравнить. При этом соответствующая входная линия перекрывается и замыкается на ЛОС, пока на входе не появится кортеж второго отношения с новым значением атрибута соединения;
удаление текущего кортежа из выходной последовательности при неуспешном сравнении (выходная линия замыкается на «землю»). Для операции соединения в выходном модуле может выполняться сцепление выходных кортежей. Режим потоковой обработки здесь обеспечивается тем, что микропрограммные процессоры (входной, компараторный и выходной) управляются входными последовательностями кортежей через изменение внутренних состояний. При этом определенная микропрограмма выполняется, если модуль находится в соответствующем состоянии, зависящем от поступления входных кортежей.
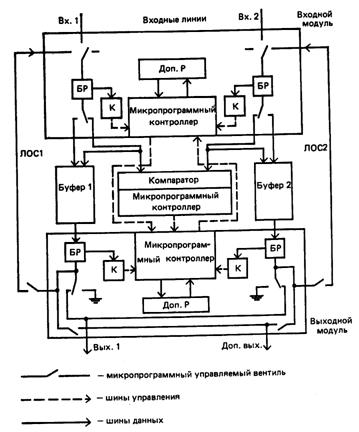
Рис. 13. Универсальный компараторный процессор для реляционных операций: БР-а-разрядныа буферный регистр; Доп. Р - дополнительный регистр; К - компаратор; ЛОС - линии обратной связи
При выполнении операции селекции в Буфер 2 загружается «псевдокортеж», соответствующий заданному условию поиска. (Очевидно, таким образом можно реализовать селекцию по условию, не содержащему дизъюнкций.) Кортежи отношения, поступающие на Вх.1, пропускаются через компаратор, а «псевдокортеж» циркулирует по ЛОС2, Буфер 2 и компаратору. Входной модуль синхронизирует этот процесс. При успешном сравнении в компараторе кортеж отношения посылается на Вых.1, иначе на «землю». Аналогично рассмотренному реализован реляционный процессор РП (см. рис. 3) в МБД Delta, но с большим разнообразием выполняемых функций.
4. Аппаратная реализация потоковой фильтрации данных непосредственно в каналах УМП. Такая фильтрация позволяет снизить объемы данных, передаваемых из массовой памяти на обработку, что является существенным источником повышения производительности МБД в целом. Потоковые процессоры фильтрации (фильтры) должны удовлетворять следующим требованиям:
скорость обработки должна соответствовать скорости чтения НМД, чтобы избежать холостых оборотов МД;
необходимость использования двух коммутируемых буферов обчаемом в одну дорожку МД для обеспечения непрерывности чтения;
возможность пропускать в выходной канал только релевантные поисковому условию данные (горизонтальная фильтрация);
возможность формировать на выходе часть входной записи в соответствии с заданным условием (вертикальная фильтрация);
задание поисковых условий в виде дизъюнктивной нормальной формы элементарных поисковых условий или в виде поисковых образов;
объем поисковых условий допилен определяться допустимой скоростью обработки.
Достаточно полный обзор существующих процессоров фильтрации.
5. Устранение препятствия в увеличении производительности многопроцессорной МБД с двумя уровнями обработки и системной буферной памятью за счет улучшения системы коммутации и связи процессоров обработки с СБП и между собой. Это определяется интенсивностью обмена данными между процессорами и СБП и объемом этих данных, которые, как правило, являются частями файлов (отношений БД). Кроме этого организация параллельной работы процессоров требует интенсивного обмена сообщениями между процессорами. Ориентировочные требования к системе коммутации в МБД с высокой степенью параллельности:
скорость передачи данных - 10-80 Мбайт/с; число подключаемых автономных банков памяти - 100; число подключаемых процессоров обработки - 100; отсутствие конфликтов.
В этой же работе дается ряд перспективных методов реализации высокоскоростных сетей коммутации (до 10^3 входов) и реализации на их основе многопортовой системной буферной памяти для МВД.
Фильтры представляют собой технические или программные средства для выделения данных, удовлетворяющих каким-либо условиям. В реляционной модели данных выбор по условию соответствует операциям проекции и селекции реляционной алгебры. В задачах обработки текста требуется, как правило, выбрать текст, содержащий данное слово. Те же задачи выбора данных по условию могут решаться и с помощью использования циклов или хэширования. Фильтры, однако, позволяют проверять более сложные условия, чем «равно» (для хэширования возможна только такая проверка), «не равно», «больше», «меньше». Фильтры не требуют предварительной структуризации данных. Вместе с тем использование фильтров предполагает полный просмотр отношения (или, если в базе хранятся инвертированные файлы, полный просмотр значений атрибутов, участвующих в условии). Фильтры могут применяться и в комбинации с индексированием и хэшированием.
Общая схема использования фильтров следующая. Процессор, анализирующий запрос, выделяет условие селекции. Выделенное условие передается в специальный процессор (или группу процессоров), который является программируемым фильтром. Этот процессор может быть как специализированным, так и процессором общего назначения.
Затем фильтр читает последовательно кортежи отношения, проверяя на них заданное условие и отбирая удовлетворяющие этому условию кортежи. Отобранные (релевантные) кортежи передаются другим процессорам для дальнейшей обработки. Обработка может осуществляться параллельно с работой фильтра.
В ряде проектов МЕД используются фильтры, которые моделируют для проверки условий конечные автоматы. При такой реализации скорость проверки условия практически не зависит от его сложности (если размер памяти фильтра достаточен для моделирования конечного автомата, проверяющего условие)
Бинарные операции (объединение, пересечение, соединение) над отсортированными отношениями также могут быть реализованы с помощью фильтров.
Специализироьанный фильтр работает приблизительно в два раза быстрее, чем происходит загрузка входного буфера с диска. В процессе загрузки фильтр может читать уже загруженную часть памяти. Кэш-память служит промежуточной для обмена между дисковой памятью и буферами.
Когда в качестве фильтрующего процессора используется процессор общего назначения, входной буфер разбивается на два. Контроллер загружает блоки входного файла поочередно в один из двух буферов. Загрузка ведется непосредственно с диска, так как фильтрация идет приблизительно в три раза медленнее чтения. Кэш-память в этом случае не нужна. Результат фильтрации записывается в один из двух выходных буферов. По заполнении буфера его содержимое сбрасывается на диск.
К недостаткам фильтров, моделирующих конечные автоматы, следует отнести высокие требования к размерам памяти фильтра.
Другой способ проверки Условий осуществляется прямым фильтром, структура которого соответствует структуре проверяемого условия. Основными блоками фильтра являются компаратор, управляющее устройство и логическое устройство. Компараторы проверяют истинность простых условий. Их число ограничено и фиксировано в аппаратуре. Современная технология СБИС позволяет строить прямые фильтры с числом компараторов порядка 100. Управляющее устройство организует работу фильтра, логическое устройство обрабатывает полученные значения и генерирует окончательное значение истинности сложного условия. На вход компаратора подается запись вида