Принципы реализации машин БДРефераты >> Программирование и компьютеры >> Принципы реализации машин БД
Отличительными особенностями данного проекта являются следующие структурные решения.
1. Метод опережающей подкачки кортежей из УМП в СБП сочетает здесь не только с первичной фильтрацией, но и со специальным распределением кортежей по банкам СЕЛ. Эта так называемая динамическая хэш-сегментация позволяет выполнять операции реляционной алгебры на уровне вторичной обработки параллельно и без обменов несколькими ПPA, так что каждый ПРА реализует бинарную операцию над парой соответствующих сегментов отношений-операндов. Это является одним из источников повышения производительности МБД при выполнении операций реляционной алгебры.
2. Включение в цикл вторичной обработки фильтров потока кортежей, используемых в цикле первичной обработки, позволяет обрабатывать промежуточные отношения в СБП, так же как и исходные отношения БД, единообразно интерпретировать последовательность операций реляционной алгебры. Таким образом, выполнение транзакции, соответствующей сложному запросу к реляционной БД, заключается в многократном выполнении циклов первичной и вторичной обработки.
3. Предварительная и параллельная фильтрация данных со скоростью их поступления из УМП позволяет снизить объем перемещаемых из УМП в СБП данных, что является существенным источником повышения производительности МБД в целом. Этот механизм используется во многих (если не во всех) проектах МН МБД и считается признанным решением.
Как показали многочисленные исследования, СУБД не может быть эффективной, если большая часть ее работает под управлением операционной системы общего назначения. Поэтому повышение эффективности МБД связано с полной изоляцией СУБД в рамках МВД, т. е. реализацией функционално-полных МВД, выполняющих все функции управления транзакциями. Учитывая сложность соответствующей операционной системы МБД, реализовать функционально полную и высокопараллельную МН МВД сложно.
Вторая основная проблема в создании высокопараллельных МН МБД, названная «дисковым парадоксом», заключается в том, что скорость ввода-вывода современных УМП (одноканальные и многоканальные НМД с перемещающимися головками) является узким местом и ограничивает достижение высокого параллелизма в обработке. В МН МБД для решения этой проблемы в качестве кэш-диска применяется большая полупроводниковая буферная память.
Для решения этой проблемы некоторые авторы предлагают сетевые МБД в которых распределенное хранение больших БД осуществляется на большем количестве НМД.
Сетевые МВД (см. рис. 1,б) воплощают принципы однородности структуры, сегментации данных в устройствах массовой памяти и распределения процессоров обработки по УМП. Таким образом, основная идея сетевых MBД - приближение дешевой обрабатывающей логики (в виде универсальных микропроцессоров) к УМП и связывание таких «обрабатывающих хранилищ» в сеть. Учитывая быстро снижающуюся стоимость процессоров oбработки и жестких НМД и успехи в технике коммуникации процессоров, в ее составе такой сети может быть сотни УМП, с каждым из которых соединен свой обрабатывающий процессор. Примерами таких проектов являются МВО; GAMMA. В перспективе развития сетевых MB.Д некоторые авторы видят создание МВД на основе вычислительной систолической среды. Так, проект NODD, схема которого изображена на рис. 5, реализован в виде регулярной решетки, в узлах которой размещены процессорные элементы (ПЭ). С каждым ПЭ связаны своя локальная память (ЛП) и устройство массовой памяти (УМП) в виде жесткого НМД.
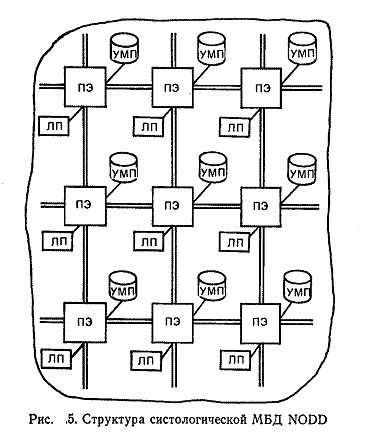
Предполагается также замена УМП энергонезависимой полупроводниковой памятью соответствующей емкости («силиконовая» систолическая МВД). Назначение ЛП в каждом узле-хранение программ обработки, копии управляющей программы, буфера для обмена сообщениями и кэш-памяти для своего УМП (3% каждого локального УМП находится в этой локальной кэш-памяти). Для целей надежности пространство на каждом УМП разделено на части: одна часть для хранения части БД, принадлежащей своему узлу, другая-дублирует данные четырех соседних узлов. Особенностью является и то, что управление выполнением транзакций в таких сетевых МВД полностью распределено, так что каждый процессор может взять на себя роль управляющего.
Особый интерес приобретает создание систолических МВД в связи с появлением серийных однокристальных транспьютеров, содержащих наряду с процессором и памятью каналы (порты ввода-вывода). Например, промышленный транспьютер фирмы INMOS IMS Т414 имеет следующие характеристики. В одном кристалле реализован 32-разрядный процессор быстродействием до 10 млн. опер./с, статическое ОЗУ на 2 Кбайт, четыре канала связи, 32-разрядный интерфейс памяти и контроллер динамического ОЗУ. Конструктивно транспьютерная матрица, являющаяся основным элементом систолических транспьютерных МВД (см. рис. 5), может быть реализована посредством серийных транспьютерных плат IMS ВОООЗ той же фирмы. Эта двойная европлата содержит четыре транспьютера Т414, связанных между собой портами связи, четыре устройства динамической памяти по 256 Кбайт каждое и четыре внешних порта ввода-вывода. Возможно, в ближайшее время применение таких транспьютерных плат переведет проекты систолических МВД из области теоретических исследований в область практической реализации.
Основной проблемой в распределенных (сетевых) МБД является оптимальная кластеризация данных по локальным УМП и поддержка соответствующей распределенной индексации. В GAMMA, например, предлагается кластеризация каждого отношения по всем УМП (в соответствии с хешированием значенийключевых атрибутов и созданием распределенного по УМП индекса этих значений). В NODD предлагается равномерное распределение отношений по узлам решетки. Между конкретными кортежами разных отношений, для которых действуют семантические связи, существуют указатели, задающие расположение связанных кортежей (номера узлов и их адреса в УМП). Таким образом, запрос в БД возбуждает связи между кортежами в узлах решетки и порождает поток данных между ними. Это позволяет реализовать в такой МВД потоковую обработку сложных запросов на основе модели «активного графа»
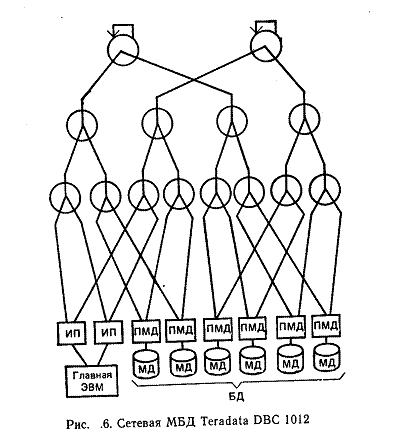
К классу сетевых относится коммерческая МВД фирмы Teradata DBC 1012, которая интенсивно распространяется и находит широкое применение в разлиных информационных системах. На рис. 6 изображена конфигурация DBC 1012 с восемью обрабатывающими процессорами ПМД (на базе i80386), каждый из которых имеет НМД и подключается к коммуникационной сети типа двоичного дерева (Y-сеть). В узлы этой сети встроены сетевые высокоскоростные процессоры и программируемые логические матрицы, реализующие функции управления сетью. Y-сеть позволяет осуществлять дуплексный обмены между обрабатывающими процессорами. В эту же сеть подключаются коммуникационные процессоры (ИЛ) для осуществления интерфейса с главной ЭВМ. Каждый обрабатывающий процессор обеспечивает поддержку всех операций реляционной алгебры, достаточных для выполнения операторов SQL, поддержку своей части БД, а также выполнение всех функций управления транзакциями над своей частью БД, в том числе защиту целостности, восстановления и т. д. Образцы DBC 1012 включают до 128 процессоров и имеют распределенную по обрабатывающим процессорам полупроводниковую память емкостью 412 Мбайт на один процессор. Общая емкость массовой памяти составляет до 1000 Гбайт и общее быстродействие - до 10^9 опер./с.