Классификация сейсмических сигналов на основе нейросетевых технологийРефераты >> Кибернетика >> Классификация сейсмических сигналов на основе нейросетевых технологий
![]() коэффициент масштабирования:
коэффициент масштабирования:
![]()
Вся процедура состоит из следующих шагов:
Для каждого нейрона последующего слоя![]() :
:
Инициализируются весовые коэффициенты (с нейронов текущего слоя):
![]() случайное число в диапазоне [-1,1] ( или
случайное число в диапазоне [-1,1] ( или ![]() ).
).
Вычисляется норма ![]()
Далее веса преобразуются в соответствии с правилом:
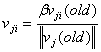
Смещения ![]() выбираются случайным образом из диапазона
выбираются случайным образом из диапазона ![]() .
.
Обе предложенные методики позволили на практике добиться лучших результатов, в сравнении со стандартным алгоритмом начальной инициализации весов.
6.5 Алгоритм обучения и методы его оптимизации.
Приступая к обучению выбранной нейросетевой модели, необходимо было решить, какой из известных типов алгоритмов, градиентный (обратное распространения ошибки) или стохастический (Больцмановское обучение) использовать. В силу ряда субъективных причин был выбран именно первый подход, который и представлен в этом разделе.
Обучение нейронных сетей как минимизация функции ошибки.
Когда функционал ошибки нейронной сети задан (раздел 6.3), то главная задача обучения нейронных сетей сводится к его минимизации. Градиентное обучение – это итерационная процедура подбора весов, в которой каждый следующий шаг направлен в сторону антиградиента функции ошибки. Математически это можно выразить следующим образом:
![]() , или , что то же самое :
, или , что то же самое : ![]() ,
,
здесь ht - темп обучения на шаге t. В теории оптимизации этот метод известен как метод наискорейшего спуска.[]
Метод обратного распространения ошибки.
Исторически наибольшую трудность на пути к эффективному правилу обучения многослойных персептронов вызвала процедура расчета градиента функции ошибки ![]() . Дело в том, что ошибка сети определяется по ее выходам, т.е. непосредственно связана лишь с выходным слоем весов. Вопрос состоял в .том, как определить ошибку для нейронов на скрытых слоях, чтобы найти производные по соответствующим весам. Нужна была процедура передачи ошибки с выходного слоя к предшествующим слоям сети, в направлении обратном обработке входной информации. Поэтому такой метод, когда он был найден, получил название метода обратного распространения ошибки (error back-propagation ).
. Дело в том, что ошибка сети определяется по ее выходам, т.е. непосредственно связана лишь с выходным слоем весов. Вопрос состоял в .том, как определить ошибку для нейронов на скрытых слоях, чтобы найти производные по соответствующим весам. Нужна была процедура передачи ошибки с выходного слоя к предшествующим слоям сети, в направлении обратном обработке входной информации. Поэтому такой метод, когда он был найден, получил название метода обратного распространения ошибки (error back-propagation ).
Разберем этот метод на примере двухслойного персептрона с одним нейроном на выходе.(рис 6.1) Для этого воспользуемся введенными ранее обозначениями. Итак,
![]() -Функция ошибки (13)
-Функция ошибки (13)
![]() -необходимая коррекция весов коррекция весов (14)
-необходимая коррекция весов коррекция весов (14)
для выходного слоя Dv записывается следующим образом.
![]()
Коррекция весов между входным и скрытым слоями производится по формуле:
![]() (15)
(15)
![]()
![]()
![]()
Подставляя одно выражение в другое получаем
![]() (16)
(16)
Производная функции активации, как было показано ранее (раздел 6.1), вычисляется через значение самой функции. ![]()
![]()
Непосредственно алгоритм обучения состоит из следующих шагов:
1. Выбрать очередной вектор из обучающего множества и подать его на вход сети.
2. Вычислить выход сети y(x) по формуле (12).
3. Вычислить разность между выходом сети и требуемым значением для данного вектора (13).
4. Если была допущена ошибка при классификации выбранного вектора, то подкорректировать последовательно веса сети сначала между выходным и скрытым слоями (15), затем между скрытым и входным (16).
5. Повторять шаги с 1 по 4 для каждого вектора обучающего множества до тех пор, пока ошибка на всем множестве не достигнет приемлемого уровня.
Несмотря на универсальность, этот метод в ряде случаев становится малоэффективным. Для того, чтобы избежать вырожденных случаев, а также увеличить скорость сходимости функционала ошибки, разработано много модификаций стандартного алгоритма, в частности две из которых и предлагается использовать.
Многостраничное обучение.
С математической точки зрения обучение нейронных сетей (НС) – это многопараметрическая задача нелинейной оптимизации. В классическом методе обратного распространения ошибки (single-режим) обучение НС рассматривается как набор однокритериальных задач оптимизации. Критерий для каждой задачи - качество решения одного примера из обучающей выборки. На каждой итерации алгоритма обратного распространения параметры НС (синаптические веса и смещения) модифицируются так, чтобы улучшить решение одного примера. Таким образом, в процессе обучения циклически решаются однокритериальные задачи оптимизации.
Из теории оптимизации следует, что при решении многокритериальных задач модификации параметров следует производить, используя сразу несколько критериев (примеров), в идеале - все. Тем более нельзя ограничиваться одним примером при оценке производимых изменений значений параметров.
Для учета нескольких критериев при модификации параметров используют агрегированные или интегральные критерии, которые могут быть, например, суммой, взвешенной суммой или квадратным корнем от суммы квадратов оценок решения отдельных примеров.
В частности, в настоящих исследованиях изменения весов проводилось после проверки всей обучающей выборки, при этом функция ошибки рассчитывалась в виде :
![]()
где,
k - номер обучающей пары в обучающей выборке, k=1,2,…,n1+n2
n1 - количество векторов первого класса;
n2 - число векторов второго класса.
Как показывают тестовые испытания, обучение при использовании пакетного режима, как правило сходится быстрее, чем обучение по отдельным примерам.
Автоматическая коррекция шага обучения.
В качестве еще одного расширения традиционного алгоритма обучения предлагается использовать так называемый градиентный алгоритм с автоматическим определением длины шага h. Для его описания необходимо определить следующий набор параметров: