Классификация сейсмических сигналов на основе нейросетевых технологийРефераты >> Кибернетика >> Классификация сейсмических сигналов на основе нейросетевых технологий
5. Методы предварительной обработки данных.
Если возникает необходимость использовать нейросетевые методы для решения конкретных задач, то первое с чем приходится сталкиваться – это подготовка данных. Как правило, при описании различных нейроархитектур, по умолчанию предполагают что данные для обучения уже имеются и представлены в виде, доступном для нейросети. На практике же именно этап предобработки может стать наиболее трудоемким элементом нейросетевого анализа. Успех обучения нейросети также может решающим образом зависеть от того, в каком виде представлена информация для ее обучения.
В этой главе рассматриваются различные процедуры нормировки и методы понижения размерности исходных данных, позволяющие увеличить информативность обучающей выборки.
5.1 Максимизация энтропии как цель предобработки.
Рассмотрим основной руководящий принцип, общий для всех этапов предобработки данных. Допустим, что в исходные данные представлены в числовой форме и после соответствующей нормировки все входные и выходные переменные отображаются в единичном кубе. Задача нейросетевого моделирования – найти статистически достоверные зависимости между входными и выходными переменными. Единственным источником информации для статистического моделирования являются примеры из обучающей выборки. Чем больше бит информации принесет пример – тем лучше используются имеющиеся в нашем распоряжении данные.
Рассмотрим произвольную компоненту нормированных (предобработанных) данных: ![]() . Среднее количество информации, приносимой каждым примером
. Среднее количество информации, приносимой каждым примером ![]() , равно энтропии распределения значений этой компоненты
, равно энтропии распределения значений этой компоненты ![]() . Если эти значения сосредоточены в относительно небольшой области единичного интервала, информационное содержание такой компоненты мало. В пределе нулевой энтропии, когда все значения переменной совпадают, эта переменная не несет никакой информации. Напротив, если значения переменной
. Если эти значения сосредоточены в относительно небольшой области единичного интервала, информационное содержание такой компоненты мало. В пределе нулевой энтропии, когда все значения переменной совпадают, эта переменная не несет никакой информации. Напротив, если значения переменной ![]() равномерно распределены в единичном интервале, информация такой переменной максимальна.
равномерно распределены в единичном интервале, информация такой переменной максимальна.
Общий принцип предобработки данных для обучения, таким образом состоит в максимизации энтропии входов и выходов.
5.2 Нормировка данных.
Как входами, так и выходами могут быть совершенно разнородные величины. Очевидно, что результаты нейросетевого моделирования не должны зависеть от единиц измерения этих величин. А именно, чтобы сеть трактовала их значения единообразно, все входные и выходные величин должны быть приведены к единому масштабу. Кроме того, для повышения скорости и качества обучения полезно провести дополнительную предобработку, выравнивающую распределения значений еще до этапа обучения.
Индивидуальная нормировка данных.
Приведение к единому масштабу обеспечивается нормировкой каждой переменной на диапазон разброса ее значений. В простейшем варианте это – линейное преобразование:
![]()
в единичный отрезок: ![]() . Обобщение для отображения данных в интервал
. Обобщение для отображения данных в интервал ![]() , рекомендуемого для входных данных тривиально.
, рекомендуемого для входных данных тривиально.
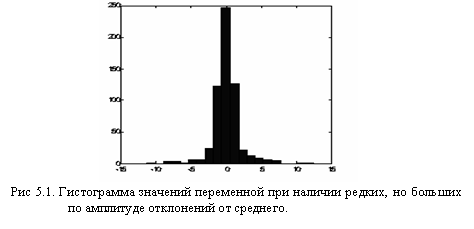
Линейная нормировка оптимальна, когда значения переменной ![]() плотно заполняют определенный интервал. Но подобный «прямолинейный» подход применим далеко не всегда. Так, если в данных имеются относительно редкие выбросы, намного превышающие типичный разброс, именно эти выбросы определят согласно предыдущей формуле масштаб нормировки. Это приведет к тому, что основная масса значений нормированной переменной
плотно заполняют определенный интервал. Но подобный «прямолинейный» подход применим далеко не всегда. Так, если в данных имеются относительно редкие выбросы, намного превышающие типичный разброс, именно эти выбросы определят согласно предыдущей формуле масштаб нормировки. Это приведет к тому, что основная масса значений нормированной переменной ![]() сосредоточится вблизи нуля
сосредоточится вблизи нуля ![]() Гораздо надежнее, поэтому, ориентироваться при нормировке не а экстремальные значения, а на типичные, т.е. статистические характеристики данных, такие как среднее и дисперсия.
Гораздо надежнее, поэтому, ориентироваться при нормировке не а экстремальные значения, а на типичные, т.е. статистические характеристики данных, такие как среднее и дисперсия.
![]() , где
, где
![]() ,
, ![]()
В этом случае основная масса данных будет иметь единичный масштаб, т.е. типичные значения все переменных будут сравнимы (рис. 6.1)
 |
Однако, теперь нормированные величины не принадлежат гарантированно единичному интервалу, более того, максимальный разброс значений ![]() заранее не известен. Для входных данных это может быть и не важно, но выходные переменные будут использоваться в качестве эталонов для выходных нейронов. В случае, если выходные нейроны – сигмоидные, они могут принимать значения лишь в единичном диапазоне. Чтобы установить соответствие между обучающей выборкой и нейросетью в этом случае необходимо ограничить диапазон изменения переменных.
заранее не известен. Для входных данных это может быть и не важно, но выходные переменные будут использоваться в качестве эталонов для выходных нейронов. В случае, если выходные нейроны – сигмоидные, они могут принимать значения лишь в единичном диапазоне. Чтобы установить соответствие между обучающей выборкой и нейросетью в этом случае необходимо ограничить диапазон изменения переменных.
Линейное преобразование, представленное выше, не способно отнормировать основную массу данных и одновременно ограничить диапазон возможных значений этих данных. Естественный выход из этой ситуации – использовать для предобработки данных функцию активации тех же нейронов. Например, нелинейное преобразование
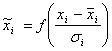 ,
, ![]()
нормирует основную массу данных одновременно гарантируя что![]() (рис. 5.2)
(рис. 5.2)
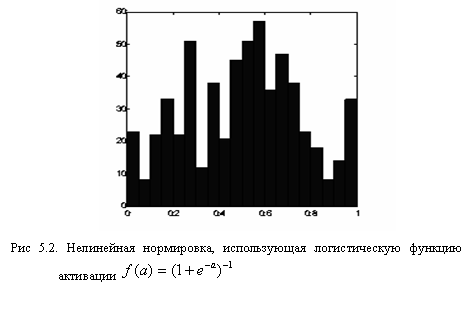 |
Как видно из приведенного выше рисунка, распределение значений после такого нелинейного преобразования гораздо ближе к равномерному.
Все выше перечисленные методы нормировки направлены на то, чтобы максимизировать энтропию каждого входа (выхода) по отдельности. Но, вообще говоря, можно добиться гораздо большего максимизируя их совместную энтропию. Существуют методы, позволяющие проводить нормировку для всей совокупности входов, описание некоторых из них приведено в [4].
6.3 Понижение размерности входов.
Поскольку заранее неизвестно насколько полезны те или иные входные переменные для предсказания значений выходов, возникает соблазн увеличивать число входных параметров, в надежде на то, что сеть сама определит, какие из них наиболее значимы. Однако чаще всего это не приводит к ожидаемым результатам, а к тому же еще и увеличивает сложность обучения. Напротив, сжатие данных, уменьшение степени их избыточности, использующее существующие в них закономерности, может существенно облегчить последующую работу, выделяя действительно независимые признаки. Можно выделить два типа алгоритмов, предназначенных для понижения размерности данных с минимальной потерей информации: