Анализ эффективности кредитных организацийРефераты >> Банковское дело >> Анализ эффективности кредитных организаций
![]()
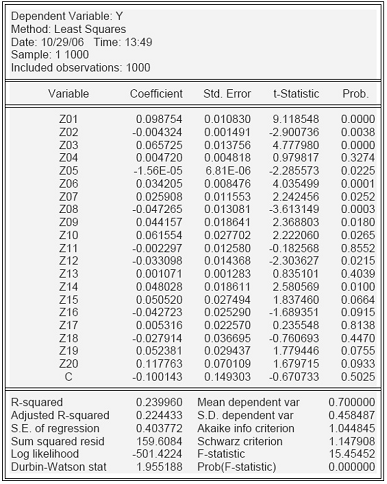
Построим регрессию Y на факторы Z1-Z20 по методу линейной регрессии (табл.14.)
Таблица 14. Оценка линейной вероятностной модели
В нашем случае прогнозные значения Yf указывают на вероятность возврата (невозврата) кредита. Построим график прогнозных значений (рис.3.)
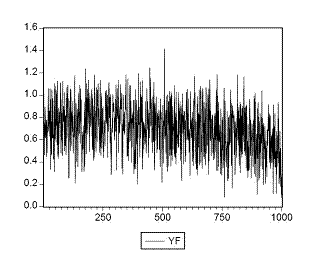
Рис.3. график прогнозных значений
Можно видеть, что прогнозные значения могут находиться вне интервала [0,1] – это главный недостаток LP модели. Поэтому приступим к построению моделей, лишенных этих недостатков.
2.8. Логистическая регрессия
Будем считать, что событие в данных фиксируется дихотомической переменной (0 не произошло событие, 1 - произошло). Для построения модели предсказания можно было бы построить, к примеру, линейное регрессионное уравнение с зависимой дихотомической переменной Y, но оно будет не адекватно поставленной задаче, так как в классическом уравнении регрессии предполагается, что Y - непрерывная переменная. С этой целью рассматривается логистическая регрессия. Ее целью является построение модели прогноза вероятности события {Y=1} в зависимости от независимых переменных X1,…,Xp. Иначе эта связь может быть выражена в виде зависимости P{Y=1|X}=f(X)
Логистическая регрессия выражает эту связь в виде формулы
![]() , где Z=B0+B1X1+…+BpXp
, где Z=B0+B1X1+…+BpXp
Название "логистическая регрессия" происходит от названия логистического распределения, имеющего функцию распределения ![]() . Таким образом, модель, представленная этим видом регрессии, по сути, является функцией распределения этого закона, в которой в качестве аргумента используется линейная комбинация независимых переменных [3].
. Таким образом, модель, представленная этим видом регрессии, по сути, является функцией распределения этого закона, в которой в качестве аргумента используется линейная комбинация независимых переменных [3].
Отношение вероятности того, что событие произойдет к вероятности того, что оно не произойдет P/(1-P) называется отношением шансов.
С этим отношением связано еще одно представление логистической регрессии, получаемое за счет непосредственного задания зависимой переменной в виде Z=Ln(P/(1-P)), где P=P{Y=1|X1,…,Xp}. Переменная Z называется логитом. По сути дела, логистическая регрессия определяется уравнением регрессии Z=B0+B1X1+…+BpXp.
В связи с этим отношение шансов может быть записано в следующем виде
P/(1-P)= ![]() .
.
Отсюда получается, что, если модель верна, при независимых X1,…,Xp изменение Xk на единицу вызывает изменение отношения шансов в![]() раз.
раз.
Механизм решения такого уравнения можно представить следующим образом
1. Получаются агрегированные данные по переменным X, в которых для каждой группы, характеризуемой значениями Xj=![]() подсчитывается доля объектов, соответствующих событию {Y=1}. Эта доля является оценкой вероятности
подсчитывается доля объектов, соответствующих событию {Y=1}. Эта доля является оценкой вероятности ![]() . В соответствии с этим, для каждой группы получается значение логита Zj.
. В соответствии с этим, для каждой группы получается значение логита Zj.
2. На агрегированных данных оцениваются коэффициенты уравнения Z=B0+B1X1+…+BpXp. К сожалению, дисперсия Z здесь зависит от значений X, поэтому при использовании логита применяется специальная техника оценки коэффициентов - взвешенной регрессии.
Еще одна особенность состоит в том, что в реальных данных очень часто группы по X оказываются однородными по Y, поэтому оценки ![]() оказываются равными нулю или единице. Таким образом, оценка логита для них не определена (для этих значений
оказываются равными нулю или единице. Таким образом, оценка логита для них не определена (для этих значений ![]() ).
).
Построим модель пробит для наших данных. Оценивание в SPSS дает результаты (табл.15.), где приведены коэффициенты оценивания.
Таблица 15. Оценка логит-модели
| B | ||
|
Step 1(a) |
schet |
,585 |
|
srok |
-,139 | |
|
histor |
,388 | |
|
naznah |
,033 | |
|
zaim |
-,181 | |
|
chares |
,239 | |
|
timrab |
,161 | |
|
vznos |
-,299 | |
|
famil |
,264 | |
|
poruchit |
,360 | |
|
timelive |
-,005 | |
|
garonti |
-,191 | |
|
vozras |
,068 | |
|
inizaimi |
,315 | |
|
kvartir |
,318 | |
|
kolzaim |
-,240 | |
|
proff |
,021 | |
|
rodstve |
-,153 | |
|
telefon |
,312 | |
|
inosmest |
1,225 | |
|
Constant |
-4,227 | |
На основе модели логистической регрессии можно строить предсказание произойдет или не произойдет событие {Y=1}. Правило предсказания, по умолчанию заложенное в процедуру LOGISTIC REGRESSION устроено по следующему принципу: если ![]() >0.5 считаем, что событие произойдет;
>0.5 считаем, что событие произойдет; ![]() £0.5, считаем, что событие не произойдет (табл.16).
£0.5, считаем, что событие не произойдет (табл.16).