Защита речевой информации в телефонных линиях связиРефераты >> Коммуникации и связь >> Защита речевой информации в телефонных линиях связи
Используя комбинацию временного и частотного скремблирования, можно значительно повысить степень закрытия речи. Комбинированный скремблер намного сложнее обычного и требует компромиссного решения по выбору уровня закрытия, остаточной разборчивости, времени задержки, сложности системы и степени искажений в восстановленном сигнале. Количество же всевозможных систем, работающих по такому принципу, ограничено лишь человеческим воображением.
В качестве примера такой системы рассмотрим скремблер, схема которого представлена на рис.7 , где операция частотно-временных перестановок дискретизированных отрезков речевого сигнала осуществляется при помощи четырех процессоров цифровой обработки сигналов, один из которых может реализовывать функцию генератора случайной последовательности (ключа системы закрытия).
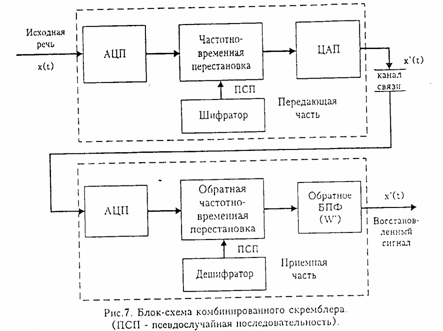
В таком скремблере спектр оцифрованного аналогово-цифровым преобразователем (АЦП) речевого сигнала разбивается посредством использования алгоритмов цифровой обработки сигналов на частотно-временные элементы, которые затем перемешиваются на частотно-временной плоскости в соответствии с одним из криптографических алгоритмов (Рис.8) и суммируются, не выходя за пределы частотного диапазона исходного сигнала.
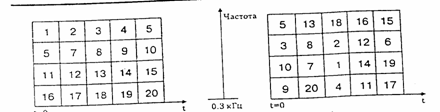
Рис. 8. Принцип работы комбинированого скремблера
В представленной на (рис.8) системе закрытия речи используются четыре процессора цифровой обработки сигналов. Количество частотных полос спектра, в которых производятся перестановки с возможной инверсией спектра, - четыре. Максимальная задержка частотно-временного элемента по времени равна пяти. Полученный таким образом закрытый сигнал при помощи цифро-аналогового преобразователя (ЦАП) переводится в аналоговую форму и подается в канал связи. На приемном конце производятся обратные операции по восстановлению полученного закрытого речевого сообщения. Стойкость представленного алгоритма сравнима со стойкостью систем цифрового закрытия речи.
Скремблеры всех типов, за исключением простейшего (с частотной инверсией), вносят искажения в восстановленный речевой сигнал. Границы временных сегментов нарушают целостность сигнала, что неизбежно приводит к появлению внеполосных составляющих. Нежелательное влияние оказывают и групповые задержки составляющих речевого сигнала в канале связи. Результатом искажений является увеличение минимально допустимого отношения сигнал/шум, при котором может осуществляться надежная связь.
Однако, несмотря на указанные проблемы, методы временного и частотного скремблирования, а также комбинированные методы успешно используются в коммерческих каналах связи для защиты конфиденциальной информации.
Дискретизация речи с последующим шифрованием
(цифровое скремблирование)
Альтернативным аналоговому скремблированию методом передачи речи в закрытом виде является шифрование речевых сигналов, преобразованных в цифровую форму, перед их передачей ( см. рис. 1-С и 1-D). Этот метод обеспечивает более высокий уровень закрытия по сравнению с описанными выше аналоговыми методами. В основе устройств работающих по такому принципу, лежит представление речевого сигнала в виде цифровой последовательности, закрываемой по одному из криптографических алгоритмов. Передача данных, представляющих дискретизированные отсчеты речевого сигнала или его параметры, по телефонным сетям, как и в случае устройств шифрования алфавитно-цифровой и графической информации, осуществляется через устройства, называемые модемами.
Основной целью при разработке устройств цифрового закрытия речи является сохранение тех ее характеристик, которые наиболее важны для восприятия слушателем. Одним из путей является сохранение формы речевого сигнала. Это направление применяется в широкополосных цифровых системах закрытия речи. Однако использование свойств избыточности информации, содержащейся в человеческой речи, более эффективно. Это направление разрабатывается в узкополосных цифровых системах закрытия речи.
Ширину спектра речевого сигнала можно считать приблизительно равной 3,3 кГц, а для достижения хорошего качества восприятия необходимое соотношение сигнал/шум должно составлять 30 дБ. Тогда, согласно теории Шеннона, требуемая скорость передачи дискретизированной речи будет соответствовать величине 33 кбит/с.
С другой стороны, структура речевого сигнала представляет собой последовательность звуков (фонем), передающих информацию. Поскольку в английском языке около 40 фонем, а в немецком - 70, то для представления фонетического алфавита потребуется 6-7 бит. Максимальная скорость произношения не превышает 10 фонем в секунду. Следовательно, минимальная скорость передачи основной технической информации речи не ниже 60-70 бит/с.
Сохранение формы сигнала требует высокой скорости передачи и, соответственно, использования широкополосных каналов связи. Например, при импульсно-кодовой модуляции (ИКМ), используемой в большинстве телефонных сетей, необходима скорость передачи, равная 64 кбит/с. В случае применения адаптивной дифференциальной ИКМ она понижается до 32 кбит/с и ниже. Для узкополосных каналов, не обеспечивающих такие скорости передачи, требуются устройства, исключающие избыточность речи до ее передачи. Снижение информационной избыточности речи достигается параметризацией речевого сигнала, при которой характеристики речи, существенные для восприятия, сохраняются.
Таким образом, правильное применение методов цифровой передачи речи с высокой информационной эффективностью является крайне важным направлением разработок устройств цифрового закрытия речевых сигналов. В таких системах устройство кодирования речи (вокодер), анализируя форму речевого сигнала, производит оценку параметров переменных компонент модели генерации речи и передает эти параметры в цифровой форме по каналу связи на синтезатор, где согласно этой модели по принятым параметрам синтезируется речевое сообщение. В таких моделях речевой сигнал представляется в виде нестационарного процесса с ограниченной скоростью изменения параметров из-за механической инерции голосовых органов человека. На малых интервалах времени (до 30 мс) параметры сигнала могут рассматриваться как постоянные. Чем короче интервал анализа, тем более точно может быть представлена динамика речи, но при этом требуется более высокая скорость передачи данных. В большинстве практических случаев используются 20-миллисекундные интервалы и достигается скорость передачи данных 2400 бит/с.
Наиболее распространенными типами вокодеров являются полосные и с линейным предсказанием. Целью любого вокодера является передача параметров, характеризующих речь и имеющих низкую информационную скорость. Полосный вокодер достигает этого путем передачи амплитуды нескольких частотных полос речевого спектра. Каждый полосовой фильтр такого вокодера возбуждается при попадании энергии речевого сигнала в его полосу пропускания. Так как спектр речевого сигнала изменяется относительно медленно, набор амплитуд выходных сигналов фильтров образует пригодную для вокодера основу. В синтезаторе параметры амплитуды каждого канала управляют коэфициентами усиления фильтра, характеристики которого подобны характеристикам фильтра анализатора. Таким образом, структура полосного вокодера базируется на двух блоках фильтров - для анализа и синтеза. Увеличение числа каналов улучшает разборчивость, но при этом требуется большая скорость передачи. Компромиссным решением обычно становится выбор 16-20 каналов при скорости передачи около 2400 бит/с.