Компьютерные вирусы и способы борьбы с нимиРефераты >> Информатика >> Компьютерные вирусы и способы борьбы с ними
Первичный ключ обозначает поле (столбец) или группу полей таблицы базы данных, значение которого (или комбинация значений которых) используется в качестве уникального идентификатора записи (строки) этой таблицы.
В теории реляционных баз данных таблица представляет собой изначально неупорядоченный набор записей. Единственный способ идентифицировать определённую запись в этой таблице — это указать набор значений одного или нескольких полей, который был бы уникальным для этой записи. Отсюда и происходит понятие первичного ключа — набора полей (атрибутов, столбцов) таблицы, совокупность значений которых определена для любой записи (строки) этой таблицы и различна для любых двух записей.
Первичный ключ в таблице является базовым уникальным идентификатором для записей. Значение первичного ключа используется везде, где нужно указать на конкретную запись. На использовании первичных ключей основана организация связей между таблицами реляционной БД. Чтобы организовать между двумя таблицами связь типа «один к одному» или «один ко многим» в одну из связываемых таблиц добавляют поле (поля), содержащее(ие) значение первичного ключа записи в связанной таблице (такое поле называют внешним ключом). Для организации связи типа «многие ко многим» создают отдельную таблицу (так называемую «таблицу связи» или «таблицу ассоциации»), каждая запись которой содержит первичные ключи двух связанных записей в разных таблицах.
Внешним ключом называется поле таблицы, предназначенное для хранения значения первичного ключа другой таблицы с целью организации связи между этими таблицами.
Пусть имеется таблицы A и B. Таблица A содержит поля a, b, c, d, из которых поле a — первичный ключ. Таблица B содержит поля x, y, z. В поле y содержится значение поля a одной из записей таблицы A. В таком случае поле y и называется внешним ключом таблицы A в таблице B.
Ограничения целостности устанавливают бизнес-правила на уровне базы данных, определяя набор проверок для таблиц системы, Эти проверки автоматически выполняются всякий раз, когда вызываются оператор вставки, модификации или удаления данных в таблице. Если какие-либо ограничения нарушены, операторы отменяются. Другие операторы транзакции остаются в отложенном состоянии и могут фиксироваться или отменяться согласно логике приложения.
30. Хранение данных и организация доступа к данным. Индексные файлы и файлы данных.
Для многих система хранения данных ассоциируется с устройствами хранения и в первую очередь с дисковыми массивами. Действительно, дисковые массивы сейчас — основные устройства хранения данных, однако не стоит забывать, что обработка информации, формирование логической структуры ее хранения (дисковых томов и файловых систем) выполняется на сервере. В процедуры доступа к данным (помимо процессоров и памяти сервера) вовлечены установленные в нем адаптеры, работающие по определенному протоколу, драйверы, обеспечивающие взаимодействие» этих адаптеров с операционной системой, менеджер дисковых томов, файловая система и менеджер памяти ОС и т. д.
Как правило, система хранения данных содержит следующие подсистемы и компоненты: непосредственно устройства хранения (дисковые массивы, ленточные библиотеки), инфраструктуру доступа к устройствам хранения, подсистему резервного копирования и архивирования данных, ПО управления хранением, систему управления и мониторинга.
Индексирование баз данных
Важнейшим элементом любой СУБД является наличие средств ускоренного поиска данных. Этот механизм обычно реализуется введением так называемых индексных файлов с расширением idх и cdx. Один файл базы данных может быть проиндексирован по нескольким полям и иметь любое число индексов. Эти файлы содержат один элемент, так называемый индексный ключ. Этот ключ позволяет отсортировать записи данных в алфавитном, хронологическом или числовом порядке для поля, по которому выполнено индексирование. Допускается индексирование и по логическим полям.
Различают два типа индексных файлов:
· простой индексный файл;
· составной индексный.
1. Простой индексный файл имеет расширение файла IDX и содержит один индексный ключ. Существуют также компактные простые индексные файлы, которые благодаря сжатию данных, занимают приблизительно в шесть раз меньше места по сравнению с обычным индексным файлом.
2. Составной (мультииндексный) файл имеет расширение CDX и может осуществлять управление одновременно несколькими индексными ключами, хранящихся в индексном выражении. Отдельные ключи называются тегами. Каждый тег имеет свое имя.
Составные файлы могут быть двух видов:
· структурный составной файл;
· обычный составной файл.
Структурный составной файл имеет такое же имя файла как и файл базы данных. Данный индексный файл всегда автоматически открывается вместе со своей базой данных. Его нельзя закрыть до ее закрытия, но можно сделать не активным.
Обычный составной файл имеет произвольное имя файла, не совпадающее с именем файла базы данных.
Индексный файл содержит ключи, которые используются для идентификации специфических записей и номеров записей, связанных с ключем. Каждый индексный файл может содержать до 65535 ключей. Индексный файл обеспечивает быстрый способ определения местополо- жения специфических записей в файле данных. Важно понять, что все ключи должны быть строками.
31.Языки описания (ЯРД), манипулирования (ЯМД) и управления доступом к данным (ЯУД)
Языковые средства СУБД, необходимы для описания данных, организации общения и выполнения процедур поиска и различных преобразований данных. Классификация
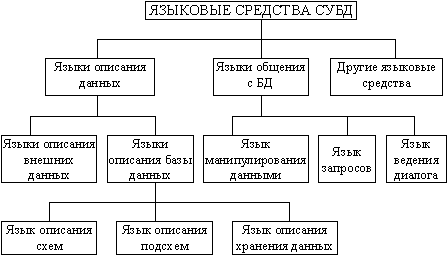
Схема имеет общий характер и ориентирована на различные СУБД. Однако на каждая СУБД, которая сейчас используется на практике и распространена на рынке программных продуктов, имеет весь набор указанных языковых средств.
Язык описания данных (DDL - Data DeSnrtton Language), предназначен для описания данных на разных уровнях абстракции: внешнем, логическом и внутреннем. Исходя из предложений COOASYL, языки описания данных на логическом (концептуальном) и внутреннем уровнях независимые и разные. Однако а большинстве промышленных СУБД языки не делится на два отдельных языка описания логической и физической организации данных, а существует единый язык, которая еще называется языком описания схем. В известных и широко используемых на практике СУБД семьи 4BASE применяется единый язык описания данных. Он предназначен для представления данных на логическом и физическом уровнях. Этот язык имеет свой синтаксис: например, имя файла не должно превышать восьми символов, а имя поля -десяти; при этом каждое имя может начинаться с буквы, поля календарной даты обозначаются символом D (DATA), символьные поля — С (CHARACTER), числовые — N (NUMERIC), логические — L (LOGICAL), примечаний — М (MEMO).
Описание всех имен, типов и размеров полей сохраняется в памяти вместе с данными; эти структуры в случае необходимости можно просмотреть и исправить. Если логический и физический уровни отделены, то в состав СУБД может входить язык описания сохранения данных В некоторых СУБД используется еще язык описания подсхем, который нужен для описания части БД, которая отражает информационные потребности отдельного пользователя или прикладной программы. В составе СУБД типа dBASE такой язык не используется.